Ахиллесова пята информационных систем
Виктор Сердюк,
ведущий инженер-программист Департамента развития технологий информационной безопасности компании РНТ
vas@rnt.ru
Современные информационные системы (ИС) — один из тех краеугольных камней, на которые опираются бизнес-процессы компаний и предприятий различных форм и назначений. Это обстоятельство заставляет уделять особое внимание вопросам защиты ИС от информационных атак, способных привести к нарушению конфиденциальности, целостности или доступности ресурсов системы.
Любые атаки нарушителей реализуются путем активизации той или иной уязвимости. Последние, присутствуя априори в системе, создают благоприятные условия для успешных атак на ИС. К числу уязвимостей относятся и некорректным образом заданная политика безопасности, и отсутствие определенных средств защиты, и ошибки в используемом ПО, и т. д. (рис. 1). В данной статье мы уделим основное внимание двум видам уязвимостей ПО, которые по значимости можно смело приравнять к известной с античных времен ахиллесовой пяте. Первый вид привносится в ПО на этапе проектирования и разработки, а второй — на этапе эксплуатации ИС.
 |
| Рис. 1. Уязвимости, информационные атаки и их последствия.
|
Уязвимости на этапе разработки
Чтобы полнее представить себе сущность таких уязвимостей, методы их выявления и устранения, обратимся к некоторым хорошо известным их типам.
Переполнение буфера
В основе уязвимости типа buffer overflow ("переполнение буфера") лежит возможность переполнения стека атакуемой подпрограммы, что дает нарушителю шанс выполнить любые команды на хосте, где она запущена.
Именно так была организована в 1988 г. первая крупномасштабная атака в Интернете, впоследствии получившая название "Интернет-червь Ч. Морриса". Атака, базирующаяся на уязвимости сетевой службы fingerd, буквально за несколько дней парализовала работу более половины компьютеров, подключенных к Интернету. И по сей день уязвимость buffer overflow считается одной из наиболее распространенных и весьма опасных для общесистемного и прикладного ПО. Для более полного представления об ее особенностях рассмотрим основные принципы организации стека процессора семейства Intel x86 (листинг 1).
|
Листинг 1. Пример вызова функции test() void test(int a, int b, int c){
char p1[6];
char p2[9];
}
void main() {
test(1,2,3);
}
|
Стек представляет собой область памяти, специально выделенной для временного хранения данных подпрограмм. В защищенном режиме работы микропроцессора максимальный размер стека ограничивается 4 Гбайт. Его структура организована по принципу LIFO (Last In First Out — "последним пришел, первым ушел"), т. е. при чтении информации первым извлекается блок данных, который был записан в стек последним. Запись информации происходит по инструкции PUSH, а чтение — по POP. При этом одна из особенностей стека заключается в том, что при записи данных он увеличивается в сторону младших адресов памяти.
Для работы со стеком используются три регистра процессора (рис. 2):
- ss — сегментный, содержащий адрес начала сегмента стека;
- sp/esp — регистр указателя, который всегда указывает на вершину стека, т. е. содержит смещение, по которому в стек был занесен последний элемент данных. Если стек пуст, то значение sp/esp равно адресу последнего байта сегмента, выделенного под стек;
- bp/ebp — регистр указателя базы кадра, обычно используемого для хранения адреса локальных переменных стека.
Значения регистров sp/esp и bp/ebp представляют собой смещения относительно сегментного регистра ss.
 |
Рис. 2. Схема организации стека.
|
Рассмотрим порядок записи данных в стек при вызове функций на примере программы, исходный текст которой приведен в листинге 1. Первая запись при вызове функции test — значения трех параметров (a, b и c) в обратном порядке (с, b, a). Затем в стек помещается адрес возврата функции, т. е. адрес инструкции, которую процессор должен выполнить по завершении работы функции test. При выходе из функции этот адрес автоматически копируется в регистр EIP (Extended Instruction Pointer), из которого процессор считывает значение и передает управление команде по адресу этого регистра. Значение регистра EBP, который указывает на вершину, и локальные переменные функции main() также сохраняются в стеке. Далее в стек записываются локальные символьные массивы p1 и p2, определенные в функции test. Итоговая структура стека функции test() показана на рис. 3.
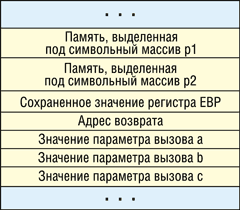 |
Рис. 3. Структура стека функции test().
|
Очевидно, что в приведенном примере уязвимость типа buffer overflow вызвана отсутствием проверки размерности данных, которые записываются в стек. В подобных случаях потенциальный нарушитель может записать в стек избыточную информацию, чтобы изменить значение адреса возврата и передать управление на фрагмент ранее внедренного вредоносного кода (листинг 2).
|
Листинг 2. Пример внесения изменения в стек для его переполнения #include <stdio.h>
int main(int argc, char **argv){
char a1[4]="abc";
char a2[8]="defghij";
strcpy(a2, "0123456789");
printf("%s
", a1);
return 0;
}
|
В приведенной программе определено два символьных массива типа char — a1 и a2. Первый массив a1 имеет размер 4 байт, второй — 8 байт. После определения переменных в программе выполняется функция strcpy, которая записывает строковое значение "0123456789" в массив a2. Но записываемое значение на 7 байт превышает размерность массива a2, что приводит к его переполнению и изменению значения массива a1, который размещен в стеке выше a2.
Рис. 4 иллюстрирует состояние фрагмента стека с переменными a1 и a2 до и после вызова функции strcpy. В левой его части показано расположение в стеке содержимого двух переменных, a1 и a2. Значения обеих завершаются символом "�", что служит признаком конца строки. После компиляции и запуска программы, приведенной в листинге 2, на экран будет выведено значение измененного массива a1, принимающее значение "89".
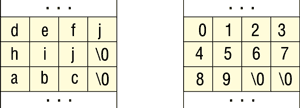 |
Рис. 4. Состояние фрагмента стека с переменными a1 и a2.
|
Часто вредоносный код, который должен быть выполнен в результате активизации уязвимости, также записывается в стек в процессе его переполнения. Как правило, в качестве такового выступает последовательность команд (shell code), выполнение которой создает удаленную консоль управления атакованным компьютером.
В общем случае существует три основных класса программ, которые могут содержать уязвимость данного типа: программы, запускаемые локально на хосте, сетевые приложения для интерактивного взаимодействия с пользователем и хранимые процедуры серверов СУБД.
Активизация уязвимости в программах первого класса позволяет нарушителю расширить свои права доступа к ресурсам локальной системы. Для активизации уязвимости сетевых приложений (CGI-модули, PHP-сценарии, активные серверные страницы ASP и т. д.) обычно формируется удаленный запрос, входные данные которого способны переполнить стек в уязвимой программе. На сервере СУБД уязвимость можно активизировать при локальном запуске хранимых процедур или при удаленном запросе к такой процедуре.
Уязвимости buffer overflow часто используются хакерами для создания Интернет-червей — самореплицирующихся программ, которые быстро распространяются по сети. Среди самых ярких примеров второй половины 2003 г. — Интернет-червь W32.Blaster.Worm (уязвимость buffer overflow в службе DCOM RPC ОС Windows 2000/XP) и W32.Slammer (СУБД Microsoft SQL Server 2000).
Вставка в SQL-запросы
Уязвимости типа SQL Injection ("вставка в SQL-запросы") позволяют злоумышленнику
выполнять несанкционированные операции с содержимым баз данных, внедрив дополнительные
команды в SQL-запросы (SQL-запрос — это последовательность команд СУБД на языке
структурированных запросов — Structured Query Language, SQL). Данная уязвимость
характерна для приложений, формирующих такие запросы к базе данных (БД), которые
получают в качестве входной информации параметры доступа к БД. Суть уязвимости
SQL Injection — отсутствие проверки корректности данных, поступающих в приложение.
В итоге становится возможным изменение входных данных хакером и искажение искомого
SQL-запроса (см. врезку "Примеры использования уязвимостей SQL Injection").
Примеры использования уязвимостей SQL InjectionЦель: получение несанкционированного доступа к ИС В ряде случаев уязвимости типа SQL Injection могут иметь место в программах,
Воспользовавшись этой ошибкой разработчика, можно путем манипуляций со "SELECT Username FROM Users WHERE Username = '' OR ''='' AND Password = '' OR ''=''" Поскольку в SQL-запрос были добавлены два новых операнда — "OR ''=''", Цель: несанкционированное извлечение данных из СУБД Для этого нарушитель может добавить в исходный текст SQL-запроса оператор SQLString = "SELECT FirstName, LastName FROM Employees WHERE City = '" & strCity & "'" Чтобы извлечь информацию и из другой таблицы, например, с именем OtherTable, SELECT FirstName, LastName FROM Employees WHERE City = '' UNION ALL SELECT OtherField FROM OtherTable WHERE ''='' После выполнения такого SQL-запроса будет сделана выборка данных из таблицы |
Форматирующая строка
Уязвимости типа format string ("форматирующая строка") характерны для приложений, использующих функции класса printf() с непроверяемым параметром форматирующей строки (последняя служит для определения общего числа параметров вызова функции, а также правил их преобразования в символьные значения). Листинг 3 иллюстрирует применение функции printf() для вывода на экран десятичных значений переменных i и j (форматирующая строка printf() содержится в строковой переменной format_string).
|
Листинг 3. Пример использования функции printf() int i = 10; int j = 20; char *format_string = "Переменная i = %d, переменная j = %d"; printf(format_string, i, j); |
Для вывода параметров форматирующей строки используется управляющий символ "%" (%d — десятичное число, %x — шестнадцатеричное значение, %n — для записи в произвольный адрес памяти значения, определяемого в программе). Каждому параметру форматирования соответствует один аргумент, который указывается сразу после форматирующей строки. Для двух параметров %d (см. листинг 3) аргументами выступают переменные i и j. Однако если в форматирующей строке определен параметр, но отсутствует его аргумент, на экран будет выведено содержимое участка стека памяти, соответствующее этому параметру.
Потенциальная уязвимость format string возникает в том случае, когда содержимое форматирующей строки не задается разработчиком, а формируется на основе непроверяемых входных параметров вызова одной из функций программы. Например, для вывода на экран строкового значения переменной str можно использовать два варианта записи функции printf(). В варианте printf("%s", str) функция задана разработчиком в явном виде, и нарушитель не может ее использовать. В варианте же printf(str) злоумышленнику легко самостоятельно сформировать значение форматирующей строки при помощи переменной str и активизировать уязвимость format string путем манипуляции со значениями параметров %x и %n.
Несанкционированное использование параметра %x позволяет получить доступ к содержимому любого участка памяти в стеке, а параметр %n дает возможность изменить адрес возврата функции, изменив значение переменной и передав управление на вредоносный код, размещенный в памяти компьютера.
Уязвимости типа format string могут быть присущи любым приложениям, которые некорректно используют функции fprintf(), printf(), snprintf(), vprintf(), vsprintf(), vsnprintf(), secproctitle() и syslog().
Эксплуатационные уязвимости конфигурации системы
Этот тип уязвимостей ИС связан с ошибками пользователей и администраторов системы при работе с общесистемным и прикладным ПО. Ниже перечислены наиболее характерные примеры таких уязвимостей.
Слабые, нестойкие пароли доступа к ресурсам ИС, которые можно раскрыть
методами полного перебора или подбора по словарю.
Наличие в системе незаблокированных встроенных учетных записей пользователей,
при помощи которых нарушитель может собрать дополнительную информацию, необходимую
для проведения атаки (таковы, например, записи Guest в ОС или Anonymous на ftp-серверах).
Неправильная установка прав доступа к информационным ресурсам. Если
по ошибке администратор дал сотруднику больше прав доступа, чем это необходимо
для выполнения его функциональных обязанностей, возможно несанкционированное
использование дополнительных полномочий для проведения атак. Например, если
пользователь имеет права на чтение содержимого исходных текстов серверных сценариев,
выполняемых на Web-сервере, то нарушитель, овладев его паролем, получает доступ
к алгоритмам работы механизмов защиты Web-приложений.
Наличие в ИС неиспользуемых, но потенциально опасных сетевых служб и программных
компонентов. Так, большая часть сетевых серверных служб (к примеру, Web-серверы
и серверы СУБД) поставляется вместе с демонстрационными версиями программ. Иногда
для их исполнения нужен высокий уровень привилегий в системе, часто и сами демо-версии
содержат уязвимости. Примеры таких программ — образцы CGI-модулей, которые поставляются
вместе с Web-приложениями, а также тестовые экземпляры хранимых процедур в серверах
СУБД.
Выявление и устранение уязвимостей
Для обнаружения уязвимостей ИС следует регулярно проводить процедуру аудита информационной безопасности, которая включает анализ текущего уровня защищенности ИС и разработку предложений по устранению выявленных уязвимостей. Собственно процедура аудита — это комплекс проверок, часть из которых направлена на обнаружение и устранение описанных выше уязвимостей.
Выявить уязвимости типа buffer overflow, SQL Injection и format string можно, либо проанализировав исходные тексты потенциально уязвимой программы, либо проведя анализ безопасности уже работающего ПО.
Первый способ предполагает экспертный анализ исходных текстов с целью поиска и исправления ошибок разработчика. В большинстве случаев для их устранения необходимо дополнить программу функциями проверки корректности входных данных. Так, для исправления уязвимостей типа buffer overflow нужно добавить процедуру контроля размера входных данных по максимальной размерности переменной, в которой они используются.
Чтобы устранить уязвимость SQL Injection, можно добавить защиту от вставки символа "'", позволяющего в большинстве случаев модифицировать исходный SQL-запрос. Для предотвращения уязвимостей типа format string разработчику программы следует всегда задавать форматирующую строку в явном виде.
Как правило, метод анализа исходных текстов отличается высокой трудоемкостью, обычно его применяют компании-разработчики ПО для поиска уязвимостей в собственных программах.
Второй метод выявления уязвимостей основан на анализе защищенности ПО, которое уже установлено и функционирует в ИС, и предполагает применение специализированных приложений — так называемых сканеров безопасности, а также систем анализа защищенности. Такие продукты широко представлены на рынке средств защиты, причем в них используются как пассивные, так и активные методы обнаружения.
Пассивный метод базируется на сборе информации о настройках, конфигурации и версиях ПО, работающего в ИС. Например, если на каком-то компьютере ИС работает операционная система без соответствующего обновления (установленного модуля Service Pack), это означает, что она подвержена уязвимостям, обнаруженным в продукте разработчиком и устраненным в данном обновлении.
Активные методы анализа защищенности имитируют информационные атаки и анализируют их результат. Сочетание пассивных и активных методов дает возможность выявить не только уязвимости типа buffer overflow, SQL Injection и format string, но и эксплуатационные ошибки конфигурации ПО.
Устранение уязвимостей обычно заключается в установке соответствующих модулей обновления (service packs, hotfixes, patches и т. д.) или в изменении настроек используемого ПО.
* * *
Безусловно, уязвимости ПО — это ахиллесова пята информационных систем, поскольку,
используя их, злоумышленники могут нанести непоправимый ущерб компании. Однако
любую потенциальную информационную атаку все же можно предотвратить при условии
своевременного выявления и устранения предпосылок к ней. Для этого не следует
пренебрегать процедурами аудита информационной безопасности ИС (как правило,
их выполняют внешние компании, работающие в области защиты информации). Необходимо
также отметить, что мероприятия по выявлению и устранению уязвимостей должны
носить не единичный, а систематический характер. Только в этом случае есть шанс
минимизировать вероятность успешной атаки на информационную систему.
Дополнительные источники информации
|