Генеративные модели ИИ и их тренировка
Модели ИИ проходят тренировку, выявляя связи и шаблоны в массивах данных из разнообразных источников, и после этого могут создавать новый контент в соответствии с выявленными шаблонами так, чтобы он был максимально похож на результат работы живого человека.
Генеративные модели искусственного интеллекта (ИИ) – это ИИ-платформы, генерирующие различный контент на базе массивов тренировочных данных, нейронных сетей, архитектуры глубокого обучения (deep learning) и указаний/команд пользователей. Это модели могут генерировать образы, визуализировать текст, синтезировать речь и звуки, создавать оригинальный видеоконтент и данные.
Модели ИИ путем самообучения либо обучения под руководством пользователей проходят тренировку, выявляя связи и шаблоны в массивах данных из разнообразных источников (интернета, книг, библиотек изображений и т.п.). После тренировки генеративные модели могут создавать новый контент в соответствии с выявленными шаблонами так, чтобы он был максимально похож на результат работы живого человека. Имитация контента, созданного человеком, достигается за счет использования нейронных сетей, воспроизводящих взаимодействие нейронов в человеческом мозгу. А когда вместе с нейронными сетями используются большие тренировочные массивы данных в сочетании со сложными алгоритмами глубокого обучения и тренировки – причем тренировки периодически повторяются и добавляются новые данные, – то модели постепенно самосовершенствуются и самообучаются.
Генеративные модели ИИ могут создавать новый текст на основе исходного, создавать изображение на основе текста, новое изображение на основе картинок и даже текст на основе изображений.
Среди генеративных моделей можно выделить три основных вида по типу тренировки: модели, которые тренируют с помощью трансформера, модели с тренировкой GAN и с тренировкой с помощью диффузии.
Модели, тренируемые с помощью трансформера
Генеративные модели ИИ на базе трансформера строятся с помощью массивных нейронных сетей и инфраструктуры трансформера, которые позволяют модели распознавать и запоминать взаимозависимости и шаблоны в последовательных данных.
Тренировка таких моделей начинается с просмотра, сохранения и «запоминания» больших наборов данных, которые получены из различных источников (это, например, размещенные в интернете тексты, онлайновые новости, статьи «Википедии», библиотеки картинок и архивы видео) и могут иметь разные форматы.
Затем модели на базе трансформера контекстуализируют все тренировочные данные и на базе выявленного контекста фокусируются на самых важных фрагментах этих данных. Результаты тренировки (выявленные взаимозависимости и шаблоны) позволяют моделям выполнять указания пользователей по генерации нового контента и формировать ответы на их вопросы.
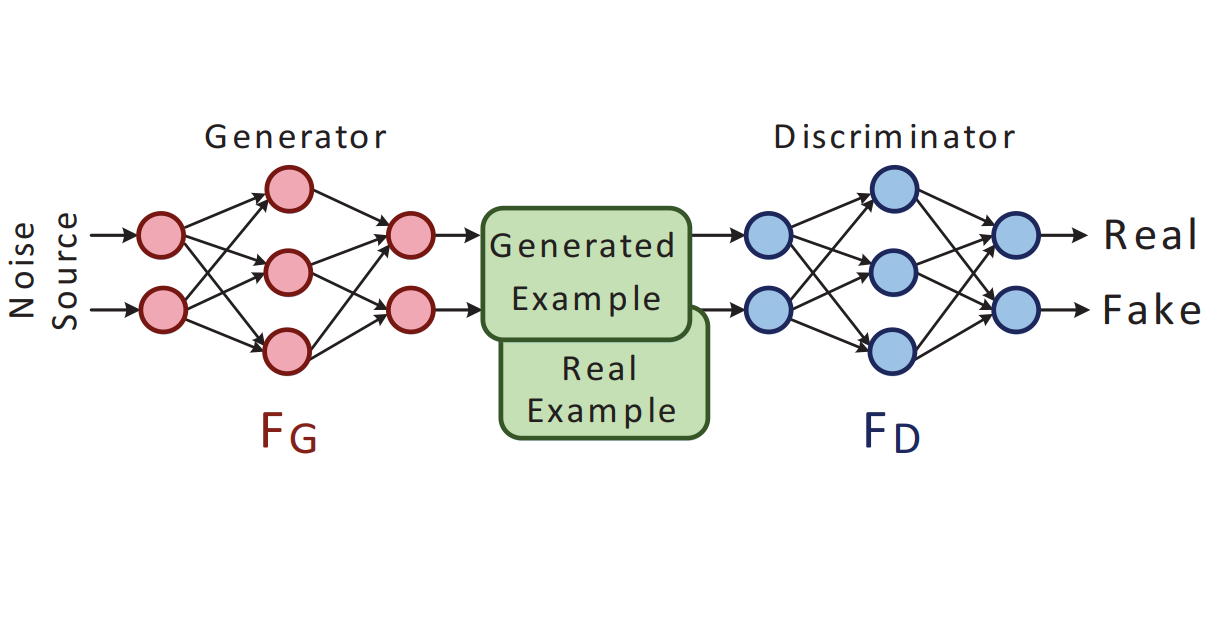
Модели с тренировкой GAN
Модели GAN (Generative Adversarial Network) тренируются с помощью двух нейросетей – так называемых генератора и дискриминатора. Генератор генерирует контент на основе введенной информации и тренировочных данных, а дискриминатор сравнивает этот контент с данными из реальных примеров, чтобы определить, насколько приближен к реальности выданный генератором контент.
Сначала генератор создает новые «фейковые» данные на основе рандомизированного сигнала шума, после чего дискриминатор вслепую сравнивает эти фейковые данные с реальными тренировочными данными, чтобы определить, какие из данных настоящие. Такой цикл генерации/сравнения повторяется до тех пор, пока дискриминатор способен отличить генерируемые данные от тренировочных.
Модели, тренируемые с помощью диффузии
Такие генеративные модели используют обычную тренировку (вперед) и тренировку в обратном направлении («диффузия вперед» и «диффузия в обратном направлении»).
При диффузии вперед к тренировочным данным добавляют рандомизированный шум, и модель тренируется на генерацию результата из зашумленных (неочищенных или специфичных) данных. Шум вносит в данные вариации и пертурбации, которые улучшают надежность модели и помогают ей выяснить, какие данные могут быть получены на выходе, если на вход поступают определенные наборы данных.
При диффузии в обратном направлении из набора исходных данных постепенно убирается шум для того, чтобы модель могла генерировать контент из оригинала данных. Этот процесс позволяет модели сфокусироваться на скрытой структуре и шаблонах оригинальных данных (а не шума), чтобы выдать желаемый результат. При постепенном удалении шума модель учится генерировать контент, который максимально близок по качеству к оригинальным исходным данным.