JDBC — действительно универсальный доступ к данным
Дмитрий Рамодин
Любому опытному пользователю известно, что иметь установленную и настроенную базу данных — это полдела; нужно еще и как-то связать с ней приложение-потребитель данных. Поэтому любая серьезная СУБД имеет описанный ее производителем интерфейс доступа. С другой стороны — на клиентской машине есть некий единый интерфейс, подчиняющийся какой-либо общеизвестной спецификации. Такой двухслойный "торт" дает возможность прикладным программистам создавать приложения, способные читать и записывать данные в самые разные базы без изменения кода. Одновременно производители БД вольны сделать такой интерфейс доступа к своему продукту, какой сочтут нужным. А для трансляции прикладных вызовов в конкретные вызовы той или иной БД между ней и приложением-клиентом устанавливают драйвер. И если вдруг случится так, что ваша организация вместо СУБД IBM DB2 задумает сделать основным хранилищем данных СУБД Oracle, для прикладных приложений в системе не изменится ровным счетом ничего. Только системному администратору придется потрудиться, переустановив драйверы доступа к новому серверу БД.
Если написанием драйверов вряд ли стоит заниматься самим, а изменение интерфейса
доступа к конкретной базе данных — дело и вовсе нереальное, то кодирование доступа
к информации из прикладной программы — задача повседневная, встречающаяся сплошь
и рядом. Поэтому в данной статье мы обратимся именно к этой теме. Причем изучать
мы будем конкретный интерфейс Java DataBase Connectivity (JDBC), разработанный
компанией Sun Microsystems (http://www.sun.com).
Выбор на данную технологию пал не случайно — это пока единственный по-настоящему
универсальный метод чтения и записи данных в БД. Все, что нужно работающему
с ним прикладному программисту, — это виртуальная машина Java и установленный
драйвер конкретного сервера баз данных. А аппаратная платформа и операционная
система не играют здесь никакой роли.
Генезис
Изначально технология JDBC была рассчитана на две категории разработчиков: прикладные Java-программисты должны были применять ее как единый и независимый интерфейс для работы с любыми видами баз данных, а поставщики этих баз, по замыслу Sun, писали бы JDBC-драйверы к своим продуктам. Нельзя сказать, чтобы эта задумка имела 100%-ный успех: некоторые производители СУБД, например Microsoft, не стали тратить время на создание своих драйверов JDBC к Microsoft SQL Server, — но в целом компьютерное сообщество отреагировало положительно, и еще на момент существования первой версии стандарта JDBC соответствующие драйверы имелись для большинства популярных СУБД. Сейчас действует спецификация JDBC 2.1 и готовится к выходу в свет JDBC 3, а жизнеспособность Java DataBase Connectivity уже проверена временем. Многие программисты по достоинству оценили легкость использования этого интерфейса, не требующего знания низкоуровневых деталей работы с памятью и соединениями и в то же время обладающего не меньшей мощью, чем, скажем, клиент доступа к серверу БД, написанный на языке C++. Многие современные драйверы JDBC не только поддерживают работу со структурированными типами данных SQL 99, но и допускают сохранение в таблицах БД целых объектов Java, а также работу с информацией, сохраняемой в обычных файлах вместо привычных таблиц.
Как работать с JDBC
Ответом на этот вопрос служит стандартная последовательность действий:
- загрузить драйвер в память виртуальной машины;
- получить соединение (Connection) с базой данных;
- подготовить выражение-запрос (Statement);
- выполнить запрос;
- разобрать полученные данные (ResultSet).
JDBC допускает использование параметризованных выражений-запросов на языке SQL, где каждый параметр можно подставлять в процессе выполнения кода. Запросов может быть сколь угодно много, а драйвер загружается всего один раз.
На рисунке приведена схема того, что можно назвать типичными случаями использования программного интерфейса JDBC. В эту схему укладывается большая часть программного кода для чтения и записи данных. А дальнейшие объяснения мы прибережем для следующих разделов.
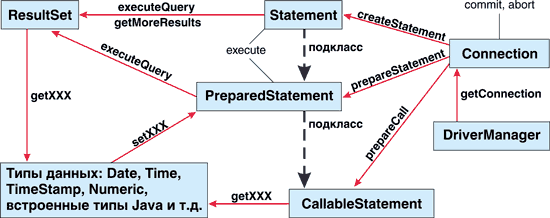 |
| Типичная схема использования программного интерфейса JDBC.
|
Загрузка драйвера и получение соединения
Чтобы использовать драйвер JDBC, его вначале следует загрузить из файла в память. Это несложно и делается всего одной строкой кода:
Class.forName("ru.sk.byte.Some_JDBC_Driver");
Чтобы этот фрагмент работал корректно, производитель драйвера должен включить в его код статический инициализатор, где бы создавался экземпляр объекта драйвера и ссылка на него регистрировалась через менеджер драйверов виртуальной машины:
public class Some_JDBC_Driver implements java.sql.Driver
{
...
static { java.sql.DriverManager.registerDriver(new
Some_JDBC_Driver()); }
...
}
Однако может случиться так, что приведенный выше фрагмент кода в выбранном вами драйвере отсутствует. Тогда придется не только загрузить класс драйвера в память, но и создать его экземпляр:
Class.forName("ru.sk.byte.Some_JDBC_Driver").newInstance();
Драйверы JDBCВсего существует четыре категории драйверов JDBC. Тип 1 — драйверы, которые реализуют интерфейс JDBC поверх другого Тип 2 — драйверы, частично написанные на Java, а частично — в Тип 3 — драйверы, реализованные целиком на Java и взаимодействующие Тип 4 — драйверы, реализованные целиком на Java и взаимодействующие |
Весьма часто класс драйвера JDBC указывают "на лету" — через опцию -D командной
строки, которая определяет среду запускаемой виртуальной машины:
java -Djdbc.drivers=Some_JDBC_Driver ClientApplication
Здесь задается системное свойство (property) с именем jdbc.drivers, значение которого и будет указывать класс драйвера для данной конкретной запускаемой виртуальной машины. Следует напомнить, что в переменной среды %CLASSPATH% должна присутствовать ссылка на данный класс или архив, в который он упакован.
Получение соединения с конкретной базой данных также возложено на менеджер драйверов. Его метод getConnection() принимает ссылку на БД, имя пользователя и его пароль:
Connection con = DriverManager.getConnection(url, "Login", "Password");
В ответ на такое обращение менеджер драйверов возвратит ссылку на экземпляр класса Connection, представляющий собой соединение с базой данных. Заметим, что формат первого параметра url отличается в разных драйверах разных производителей; чтобы задать его корректно, следует обратиться к документации, поставляемой вместе с выбранным драйвером JDBC.
Подготовка выражения-запроса
Как видно из рисунка, следующим логическим шагом после получения ссылки на класс-соединение с базой данных будет подготовка выражения-запроса (в дальнейшем просто запроса). Они представлены в JDBC тремя интерфейсами: Statement, PreparedStatement и CallableStatement.
Statement — этот интерфейс используется чаще всего и предназначается
для разового выполнения статических запросов. Следующий фрагмент кода демонстрирует
подобную технику:
Statement stmt = con.createStatement();
ResultSet result = stmt.executeQuery("SELECT NAME,
ADDRESS FROM PEOPLE");
Сначала при помощи вызова метода createStatement() интерфейса Statement создается экземпляр запроса. После этого интерфейс запроса используется для задания выражения выборки данных из таблицы БД на языке SQL, и метод executeQuery() отправляет запрос на сервер баз данных, а от последнего получает результирующую выборку записей в виде экземпляра класса ResultSet.
Данный пример работы с программным интерфейсом JDBC типичен. В табл. 1 перечислены наиболее интересные методы интерфейса Statement, в том числе и обеспечивающие другие способы работы с запросами и результатами их выполнения.
Таблица 1. Часто используемые методы интерфейса Statement
| Метод | Назначение |
| void addBatch(String sql) | Добавляет команду SQL к текущей группе |
| void cancel() | Отменяет текущий объект Statement, если и СУБД, и драйвер поддерживают эту возможность |
| void clearBatch() | Очищает текущую группу |
| void clearWarnings() | Очищает все предупреждения, касающиеся текущего объекта Statement |
| void close() | Немедленно освобождает базу данных текущего объекта Statement и ресурсы JDBC, не дожидаясь, пока это будет сделано автоматически |
| boolean execute(String sql) | Выполняет запрос SQL, который может вернуть множественный результат. Возвращает true, если в процессе выполнения запроса получена выборка данных ResultSet (в других случаях результат — это счетчик обновлений либо результат отсутствует) |
| int[] executeBatch() | Выполняет группу команд, и если все они завершились удачно, возвращает массив счетчиков обновлений |
| ResultSet executeQuery(String sql) | Выполняет запрос и возвращает класс, представляющий собой выборку данных |
| int executeUpdate(String sql) | Служит для выполнения SQL-запросов INSERT, UPDATE и DELETE. Возвращает число обработанных строк в таблице БД |
| Connection getConnection() | Возвращает ссылку на соединение, через которое был получен данный объект Statement |
| boolean getMoreResults() | Перемещается к следующему результату выполнения запроса. Возвращает true, если следующий результат — выборка данных ResultSet (в других случаях результат — это счетчик обновлений либо больше нет результатов) |
| int getQueryTimeout() | Возвращает число секунд, отпущенное на ожидание результатов выполнения запроса |
| ResultSet getResultSet() | Возвращает текущий результат выполнения запроса в виде выборки данных ResultSet |
| int getUpdateCount() | Возвращает текущий результат выполнения запроса в виде счетчика запросов |
| SQLWarning getWarnings() | Получает первое предупреждение, сгенерированное в процессе выполнения запроса |
| void setCursorName(String name) | Устанавливает имя для SQL-курсора |
| void setQueryTimeout(int seconds) | Устанавливает число секунд, отпущенное на ожидание результатов выполнения запроса |
PreparedStatement — это более развитый вид запроса. Кроме того, что
он предварительно компилируется и кэшируется сервером баз данных, PreparedStatement
может принимать подставляемые в SQL-выражения параметры:
PreparedStatement p_stmt = con.prepareeStatement( "SELECT * FROM CUSTOMERS WHERE ID = ? AND LAST_NAME LIKE ?"); p_stmt.setInt(1, 12345); p_stmt.setString(2, "Пупкин") p_stmt.execute();
Первая строка создает собственно запрос. Здесь знаки вопроса означают место в SQL-выражении, куда должно быть подставлено значение параметра, поэтому вопросительный знак называют маркером параметра. Вторая строчка подставляет вместо маркера значения параметра. Метод setInt() указывает на то, что подставляемый параметр имеет целочисленный тип. Собственно значение находится во втором параметре; первый же параметр указывает номер маркера в запросе. В данном случае это первый маркер, располагающийся после ключевого слова WHERE. Порядковый номер маркера вычисляется слева направо. В результате подстановки метод execute() пошлет СУБД следующее выражение SQL:
SELECT * FROM CUSTOMERS WHERE ID = 12345 AND LAST_NAME LIKE "Пупкин"
Кстати, когда вы узнаете, что PreparedStatement годится и для выполнения запроса без параметров, то, скорее всего, у вас возникнет вопрос: когда какой тип интерфейса лучше использовать? Ответ прост: если вы планируете запускать один и тот же запрос несколько раз, используйте PreparedStatement. В остальных случаях подойдет и просто Statement.
CallableStatement — запросы этого типа используются для вызовов хранимых
процедур (stored procedures), которые, как известно, нужны для того, чтобы переместить
вычислительную нагрузку с клиента на сервер и чтобы упростить работу с часто
используемыми операциями. Однако сначала несколько слов о параметрах при вызовах
хранимых процедур. Они могут быть входящими (in), исходящими (out) или двунаправленными
(inout). Параметры первого типа служат для передачи значений в процедуру, второго
— для возврата значений из нее, а двунаправленные параметры могут делать и то
и другое. В выражениях вызова хранимых процедур вместо любых параметров пишутся
уже знакомые нам маркеры (вопросительные знаки). Сами же выражения заключаются
в фигурные скобки, и перед именем вызываемой процедуры пишется ключевое слово
call. Пример будет приведен ниже.
Для подготовки запроса, в котором вызывается хранимая процедура, используется метод prepareCall() класса Connection.
CallableStatement c_stmt = con.prepareCall(
{ call some_stored_procedure }" );
Здесь вы видите, как происходит подготовка вызова хранимой процедуры с именем some_stored_procedure без параметров и без возврата результата.
Если вы задумали передавать или получать параметры, придется немного повозиться. Дело в том, что без проблем устанавливаются только входящие, in-параметры — нужно лишь вызвать соответствующий типу данных метод setXXX(), скажем, setFloat(), или что-то похожее. Первым параметром будет номер маркера выражения, куда нужно подставить значение, а во втором параметре передается само значение. Что же касается исходящих, out-параметров, то они должны быть зарегистрированы методом registerOutParameter(), у которого первый параметр указывает номер маркера выражения для регистрируемого параметра, а второй ссылается на константу, указывающую, какого типа параметр будет возвращен. С этой целью в классе java.sql.Types задан целый набор констант, имя каждой из которых совпадает с именем описываемого ею типа в языке SQL.
Самое непростое — двунаправленные, inout-параметры, которые следует и зарегистрировать вызовом метода registerOutParameter(), и установить методом setXXX().
Фрагмент кода, показанный ниже, демонстрирует подготовку вызова хранимой процедуры some_stored_procedure, где первый параметр возвращает строчное значение, а второй принимает и возвращает значение с плавающей точкой. Результатом вызова процедуры будет ссылка на Java-объект:
CallableStatement c_stmt = con.prepareCall( "
{ ? = call some_stored_procedure ( ? ? ) }" );
c_stmt.registerOutParameter( 1, Types.JAVA_OBJECT );
c_stmt.registerOutParameter( 2, Types.VARCHAR );
c_stmt.setInt( 3, 3.14F );
c_stmt.registerOutParameter( 3, Types.FLOAT );
Выполнение запроса
Обратили ли вы внимание на то, что запрос можно выполнить тремя различными способами? Для этого у класса Statement и его наследников PreparedStatement и CallableStatement имеются три метода. Все они предназначены для разных ситуаций:
- execute() — лучше всего подходит для запросов, когда предполагается возврат
множественных значений; - executeQuery() — выполняет запрос, результатом которого будет возврат одной
выборки данных; - executeUpdate() — служит для запуска запросов, которые изменяют таблицы
или значения столбцов и записей.
Последний метод заслуживает более пристального внимания. Во-первых, с его помощью выполняются запросы INSERT (добавить), UPDATE (обновить) и DELETE (удалить). Во-вторых, если вы хотите создать, удалить или обновить сами таблицы через выражения CREATE TABLE, DROP TABLE и ALTER TABLE соответственно, это тоже должно делаться вызовом executeUpdate().
Получение результата
Предположим, запрос был успешно выполнен и СУБД возвратила вам некоторый результат. Как его узнать? Опять-таки это зависит от того, какой был запрос и каким методом он выполнялся. Проще всего иметь дело с executeQuery(), который возвращает ссылку на специальный класс результата — ResultSet. Тогда остается только воспользоваться его методами, чтобы считать возвращенное значение. Для этого в цикле считывают значения, пока метод next() класса ResultSet не вернет false:
while( result.next() )
{ System.out.println( result.getString("FULL_NAME")); }
Отметим, что класс ResultSet оснащен различными методами getXXX() для чтения самых разных типов данных. Нужно только передать этому методу в качестве параметра либо имя читаемого столбца таблицы базы данных, либо ее порядковый номер в записи (отсчет идет от единицы). Следует также обратить внимание на то, что считывать значения столбцов нужно слева направо в том порядке, как они идут в таблице БД. Следующий код делает выборку всех записей из таблицы TOOLS со столбцами FIRST_COL, SECOND_COL, THIRD_COL и FORTH_COL и распечатывает каждую запись столбец за столбцом:
PreparedStatement p_stmt = con.prepareeStatement(
"SELECT * FROM TOOLS");
ResultSet result = p_stmt.executeQuery();
while( result.next() )
{
System.out.print ( result.getString("FIRST_COL") );
System.out.print ( result.getBoolean("SECOND_COL") );
System.out.print ( result.getDate("THIRD_COL") );
System.out.println ( result.getTime("FORTH_COL") );
}
После окончания работы с результирующей выборкой данных желательно закрыть ее, вызвав метод close(). Конечно, драйвер JDBC может и сам позаботиться о корректном закрытии результата и освобождении ресурсов, но это потребует больших вычислительных ресурсов, что нежелательно. Аналогично методом close() закрываются запросы и соединения.
Хорошей альтернативой перебора выборки может быть работа с другими методами — курсорами, которые позволяют читать записи в произвольном порядке. Во время вызова методов createStatement() и prepareStatement() можно задать опции курсора, но это выходит за рамки данной статьи. А вот посмотреть в табл. 2 на методы управления курсором класса ResultSet весьма полезно.
Таблица 2. Методы управления курсором класса ResultSet
| Метод | Назначение |
| Boolean absolute(int row) | Перемещает курсор на строку выборки с номером, заданным параметром row |
| void afterLast() | Устанавливает курсор прямо за самой последней записью в выборке |
| void beforeFirst() | Устанавливает курсор непосредственно перед самой первой записью в выборке |
| void deleteRow() | Удаляет запись, на которую указывает курсор |
| Boolean first() | Устанавливает курсор на самую первую запись выборки |
| String getCursorName() | Возвращает имя курсора |
| int getRow() | Возвращает порядковый номер строки, на которую указывает курсор |
| Boolean isAfterLast() | Возвращает true, если курсор установлен после самой последней записи в выборке |
| Boolean isBeforeFirst() | Возвращает true, если курсор находится непосредственно перед самой первой записью в выборке |
| Boolean isFirst() | Возвращает true, если курсор указывает на первую запись в выборке |
| Boolean isLast() | Возвращает true, если курсор указывает на последнюю запись в выборке |
| Boolean last() | Указывает на последнюю запись в выборке |
| void moveToCurrentRow() | Перемещает курсор на запомненную позицию, обычно на текущую запись |
| void moveToInsertRow() | Перемещает курсор на позицию вставки |
| boolean next() | Перемещает курсор на следующую запись в выборке |
| boolean previous() | Перемещает курсор на предыдущую запись в выборке |
| void refreshRow() | Делает текущей самую свежую запись |
| boolean relative(int rows) | Сдвигает курсор на rows записей от текущей позиции (отрицательное значение перемещает курсор в обратном направлении) |
Изменение данных
Здесь допускаются два варианта: через составление UPDATE-запросов или программно. Первый способ довольно прост и состоит в формировании выражения обновления и запуска его методом executeUpdate() интерфейса Connection или его наследников:
stmt.executeUpdate( "UPDATE TOOLS SET CONSTANTS_COL = 3.14 WHERE NAME_COL LIKE 'Pi'";
Однако зачастую удобнее применять обновляемую выборку. Чтобы создать ее, в процессе подготовки запроса нужно указать специальную константу CONCUR_UPDATABLE, описанную в интерфейсе ResultSet:
Statement stmt = con.createStatement( ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE );
Эти и другие полезные константы из ResultSet описаны в табл. 3.
Таблица 3. Константы интерфейса ResultSet
| Имя | Назначение |
| static int CONCUR_READ_ONLY | Выборка может только читаться, но не изменяться |
| static int CONCUR_UPDATABLE | Выборка может обновляться и изменяться |
| static int FETCH_FORWARD | Указывает на то, что записи в выборке будут располагаться в прямом порядке — от первой к последней |
| static int FETCH_REVERSE | Указывает на обратный порядок следования записей в выборке — от последней к первой |
| static int FETCH_UNKNOWN | Задает произвольный порядок записей в выборке |
| static int TYPE_FORWARD_ONLY | Дает возможность передвигать курсор по выборке только вперед |
| static int TYPE_SCROLL_INSENSITIVE | Делает выборку скроллируемой, но изменения, сделанные другими пользователями в то время, когда она открыта, не будут отражены |
| static int TYPE_SCROLL_SENSITIVE | Выборка скроллируемая и все изменения, сделанные другими пользователями в то время, когда она открыта, отражаются |
Если у вас есть обновляемая выборка, то изменить в ней значение какого-то столбца
не составляет труда. Нужно лишь установить курсор на требуемую запись и вызвать
соответствующий метод updateXXX(), где XXX — тип обновляемого значения. В интерфейсе
ResultSet имеется больше десятка таких методов для различных типов SQL. Первый
их параметр задает столбец в записи, а второй — присваиваемое новое значение.
Важно знать правила обновления. Если вы вызвали метод updateXXX(), то это еще не означает, что значение в столбце БД изменилось. Стоит вам переместить курсор, как изменения будут отброшены. Вы и сами можете откатить сделанные обновления, вызвав метод cancelRowUpdates(). Поэтому для фиксации изменений вызывают метод updateRow():
result.updateInt(3, 12345); result.updateRow();
Следующая операция, которую мы рассмотрим, — это добавление новой записи. Принципиально оно не отличается от изменения значения за исключением того, что сначала курсор переводится на специальную запись, называемую записью добавления — это программная абстракция, представляющая новую запись. Вы просто заполняете ее поля и вызываете метод insertRow() для фиксации изменений:
result.moveToInsertRow();
result.updateInt("LIST_NUMBER", 12345);
result.updateString("NAME", "Иван Пупкин");
result.insertRow();
Самая простая операция — удаление строки. Как обычно, сначала курсор позиционируется на выбранную запись, после чего вызывается метод deleteRow(). Данные строки удаляют последнюю запись:
result.last(); result.deleteRow();
* * *
Завершая краткий обзор технологии доступа к данным JDBC, хотелось бы адресовать
читателей к ее спецификации (http://java.sun.com/products/jdk/1.2/docs/guide/jdbc),
где можно найти многое из того, о чем мы не смогли здесь поговорить из-за ограниченности
объема статьи: множественное обновление, работа с большими полями типов BLOB/CLOB,
управление транзакциями и т.п. Это действительно интересно!