Технологии извлечения знаний Fulcrum
Андрей Колесов
Канадская компания Fulcrum Technologies с момента своего создания в 1984 г. специализировалась на разработке поисковых средств для текстовых документов. И за полтора десятка лет она добилась существенных успехов: по данным аналитических агентств, в 1998 г. ей принадлежало до 30% американского рынка подобных систем и около 50% — европейского.
Логичным развитием бизнеса Fulcrum стало ее вхождение в 1998 г. в состав компании
PC DOCS, одного из лидеров в области систем управления документами (в этом же
году технологии Fulcrum были впервые представлены на российском рынке). А еще
спустя год PC DOCS была приобретена компанией Hummingbird, которая именно с
этого момента вышла на лидирующие позиции в области корпоративных порталов (см.
статью ">"Полет "Колибри", "BYTE/Россия" №
2/2001). Некоторые эксперты отмечали любопытный момент в этой сделке: по их
мнению, фирму Hummingbird интересовали не столько программные системы управления
документами PC DOCS, сколько поисковые технологии Fulcrum. В результате, опоздав
с покупкой Fulcrum, Hummingbird была вынуждена купить всю PC DOCS, причем не
традиционным путем обмена акций, а за наличные деньги!
Так или иначе, но средства Fulcrum (в переводе с английского — "точка опоры", та самая, которая нужна была Архимеду, чтобы перевернуть Землю) сохранили собственную торговую марку и представляют собой самодостаточное семейство продуктов (хотя одно из направлений развития этого семейства — продолжение его интеграции с портальными технологиями Hummingbird).
Состав семейства
Ключом к пониманию технологий Fulcrum можно считать девиз, сформулированный более десяти лет назад: "Одна точка доступа к любой информации через любую платформу, на любом языке". Действительно, эти технологии поддерживают широкий спектр аппаратно-программных платформ, работу с различными источниками данных и более чем 200 форматами документов, а также обработку многоязыковых документов (практически все европейские языки, арабский, японский, корейский и многие другие). Яркий пример — применение технологий Fulcrum в государственных структурах Швейцарии, где используются одновременно четыре языка (не считая английского).
Одна из ключевых особенностей технологии заключается в следующем: информация из различных источников не загружается в специальную "систему управления знаниями", а наоборот, на сеть источников накладывается единая информационно-поисковая система, обеспечивающая прозрачный поиск и категоризацию документов. Технологии Fulcrum в настоящее время реализованы в двух основных продуктах: SearchServer 5.0 и KnowledgeServer 4.0.
SearchServer — это мощный механизм индексирования и поиска текстовой
информации с применением параллельной обработки данных (рис. 1), который служит
ядром всего семейства. Данный продукт предназначен в первую очередь для встраивания
в различные пользовательские приложения. Однако у него есть и пользовательский
интерфейс, обеспечивающий просмотр документов более чем 200 форматов с помощью
средства Fulcrum FullView. Новый конвертор INSO Outside-In Export позволяет
преобразовывать оригинальные документы в HTML-формат.
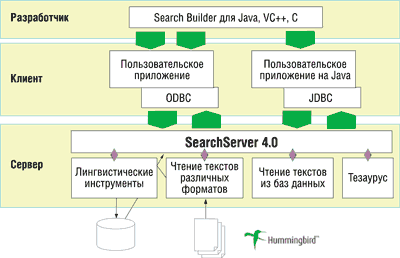 |
Рис. 1. Структура Fulcrum SearchServer.
|
Новое поисковое ядро в версии 5.0 поддерживает параллельную обработку поисковых запросов для множественных таблиц на нескольких процессорах. Помимо традиционных логических операторов, в запросе можно задавать ограничение расстояния между словами, использовать метасимволы (wildcards), весовые коэффициенты для отдельных слов, встроенный многоязычный тезаурус. Технология полнотекстового поиска Fulcrum WordSense, основанная на семантических сетях, автоматически преобразует запросы на естественных языках в логическую расширенную форму.
Архитектура данных SearchServer напоминает реляционную базу данных, где информация структурируется при помощи таблиц, каждая строка в которых соответствует документу или объекту. Однако в отличие от традиционных СУБД SearchServer не сохраняет документы в своих таблицах физически, создавая лишь их индекс. Администрирование выполняется с помощью графического средства SearchServer Administrator.
Для взаимодействия с приложениями независимых разработчиков существует программный интерфейс на специальном языке запросов SearshSQL, реализованном на базе протоколов ODBC и JDBC. Для макетирования, разработки и развертывания решений на базе SearchServer можно использовать инструмент SearchBuilder, совместимый с такими популярными средами, как Visual Basic, Visual C++ и Java.
KnowledgeServer — это законченный продукт, позволяющий развертывать
многосерверные распределенные конфигурации; он решает следующие основные задачи:
- сквозной поиск информации по множеству источников данных вне зависимости
от их формата; - интуитивный поиск документов, аналогичных заданному шаблону;
- представление всех информационных ресурсов предприятия в виде единого систематизированного
иерархического оглавления (Enterprise Table of Contents); - автоматическое отслеживание поступления новых документов по заданным темам
с помощью специальных агентов — ProActive Agents; - автоматическое создание аннотаций и категоризация документов.
Взаимодействие с источниками данных выполняется через специальные компоненты-активаторы (рис. 2). Топология подключенных ресурсов в системе представляется в виде Карты знаний, которую пользователь может преобразовать в иерархический набор собственных папок, отражающих бизнес-логику решаемых задач (рис. 3). Специальный модуль Knowledge Manager Workstation служит для автоматической категоризации (рубрикации) документов. Взаимодействие с пользовательскими местами выполняется либо через интерфейс Fulcrum Object Library, либо через новую клиентскую среду Fulcrum Solo. С помощью набора Knowledge Builder Toolkit можно разрабатывать собственные пользовательские приложения, подключаемые к серверу через программный API-интерфейс.
 |
| Рис. 2. Структура Fulcrum KnowledgeServer.
|
 |
Рис. 3. Создание Карты знаний.
|
Fulcrum KnowledgeServer построен на иерархической модели, включающей несколько уровней.
Предприятие знаний (Knowledge Enterprise) — коллекция из одного или
нескольких сайтов знаний, которые обслуживают одну организацию или предприятие.
Если сайтов больше одного, существует возможность распределенного поиска по
всем ним.
Сайт знаний (Knowledge Site) — один или несколько серверов знаний, сконфигурированных
так, чтобы работать как единое целое. Сайт всегда имеет один главный сервер
и, возможно, несколько вспомогательных. Односерверные сайты знаний можно расширить
в многосерверные — для этого нужно просто добавить новую машину и сконфигурировать
сервисы.
Сервер знаний (Knowledge Server) — это компьютер, на котором запущены
сервисы сайта знаний. Сервер знаний в составе сайта может быть главным или вспомогательным.
Концепция главных и вспомогательных серверов — это новшество Fulcrum KnowledgeServer
4.0.
Сервисы (Services) — это задачи, которые может выполнять сайт знаний
(например, маршрутизация, индексирование, поиск и т. д.).
Масштабируемость технологии Fulcrum можно проиллюстрировать на реальном примере крупной европейской компании: система Knowledge Enterprise обрабатывает 4 Тбайт (число знаков!) текстовых данных на 60 серверах Exchange на 6 площадках для 20 тыс. пользователей. Среднее время отклика при запросе на распределенный поиск — около 40 с.
Из отечественной практики
Зарубежный опыт — это очень хорошо. А как обстоит дело с использованием технологий Fulcrum в России? Вот что говорит Станислав Макаров, генеральный директор компании HBS — дистрибьютора Hummingbird в России: "Наши заказчики из числа тех, кто уже давно использует систему управления документами DOCS Open или DOCSFusion, накопили достаточно большие объемы документов, и им требуется инструмент, который позволил бы извлекать полезные знания из хранилищ документов. Это вполне логичный переход — от управления документами к управлению знаниями".
Действительно, по моим сведениям, технологии Fulcrum используются в России пока не очень широко, хотя многие организации, особенно из числа тех, кто внедрил у себя системы управления документами DOCS Open/Fusion, внимательно приглядываются к ним. Тем не менее реальные примеры имеются и в нашей стране (а это очень важно в плане демонстрации поддержки русского языка). Правда, внедрены эти технологии пока в организациях, которые не очень любят афишировать свои достижения. Поэтому здесь я приведу некий гипотетический пример, в основе которого лежат вполне реальные технические характеристики.
Итак, предположим, что некий крупный коммерческий банк хотел бы расширить свои инвестиционные программы на всю территорию России, и поэтому ему нужно отслеживать социально-экономическую ситуацию в регионах. В качестве одного из средств такого мониторинга решено формировать собственный фонд региональных СМИ (ФРСМИ) и автоматически анализировать содержание публикаций с тем, чтобы оценивать ситуацию в них с тремя градациями: "благоприятная", "нейтральная", "неблагоприятная".
Обратите внимание, что, обсуждая этот пример, мы обойдем молчанием очень важный вопрос: каким образом отбираются издания (формируется справочник изданий). Очевидно, что анализировать все издания подряд нельзя, да и не следует. Нужно выбрать некий минимальный состав источников, адекватно и наиболее полно отражающий ситуацию. Например, не нужно, с одной стороны, включать в список издания, не связанные с интересующей нас темой (например, детские журналы), а с другой — включать дублирующие, очень похожие СМИ. В общем, создание справочника изданий — это отдельная задача (которая тем не менее решается с помощью тех же средств анализа текстов).
Общая последовательность обработки документов в нашем случае будет проходить в два этапа: формирование ФРСМИ и последующая работа с ним. Обратите внимание, что собственно технологии Fulcrum используются на втором этапе. Fulcrum может работать с источниками данных и напрямую. Однако в данном случае мы решили создавать собственную базу данных закачиваемых документов, что обеспечивает высокую скорость работы и независимость от существования внешних архивов, а также качества исходной информации.
Для решения последней задачи при вводе исходных документов выполняется следующий
цикл их предварительной обработки:
- идентификация кодовой таблицы;
- идентификация формата;
- устранение дублирующих сообщений;
- анализ структуры документов;
- контроль целостности.
Далее формируются таблицы РСМИ с выделением заданных нами ключевых полей (автор,
дата, название и т. п.), для чего служат следующие операции с использованием
SearchServer:
- нормализация регистра;
- фильтрация стоп-слов;
- контроль орфографии;
- автоматическое рубрицирование;
- индексирование.
В нашем случае получилось, что средний объем формируемых таблиц составляет около 10 Гбайт/год, а объем индекса — 6 Гбайт/год. Средняя скорость индексирования — 200 Мбайт/ч на двухпроцессорной системе Pentium Xeon 500 МГц и 1024 Мбайт оперативной памяти в среде Microsoft Windows NT Server 4.0, Microsoft SQL Server 6.5 и IIS 4.0.
Создание рубрикатора выполнялось с помощью SearchServer и обучающей выборки документов из почти 250 документов. В результате была построена семантическая сеть (нейросеть), включающая около 2000 слов с набором соответствующих связей и весовых коэффициентов (рис. 4). Для формирования расширенных лингвистических запросов использовались словари-тезаурусы и средства морфологической очистки. С их помощью запрос, например, "дорожно-транспортные происшествия" расширяется в 150 раз (рис. 5).
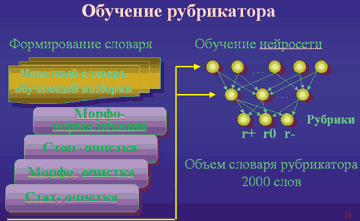 |
Рис. 4. Методика обучения рубрикатора.
|
 |
Рис. 5. Формирование расширенного лингвистического запроса.
|
Тестирование показало вполне приемлемые результаты работы системы: при росте числа активных пользователей с 1 до 50 время ответа на запрос увеличивалось с 3 до 15 с, а с расширением слов в критерии запроса время ответа росло линейно с коэффициентом 0,5.
Благодаря созданию структурированной базы данных текстовых документов можно было использовать OLAP-сервер, подключенный к Fulcrum SearchServer через стандартный API. Создание гиперкуба по четырем измерениям на основе 60 тыс. документов (рис. 6) занимает в среднем около 5 мин, а время доставки документа для просмотра на OLAP-клиенте — не более 3 с.
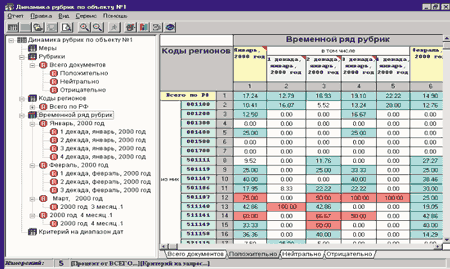 |
Рис. 6. Анализ построенного многомерного куба.
|
Убедившись в эффективности методов анализа ситуации на рынке при помощи технологий управления знаниями, руководство банка решило внедрить Fulcrum KnowledgeServer для постоянного мониторинга информации в разнородных источниках. Объем внутренней базы данных сервера оптимизируется за счет использования программируемых агентов, которые автоматически отслеживают изменение содержимого заданного списка источников, скачивая наиболее интересные (по заданным критериям) документы.