Архитектура Marathon Assured Availability
Игорь Колбин
В наше время эффективность деятельности предприятия напрямую зависит от работоспособности его информационной системы, и это диктует необходимость создания технологий, обеспечивающих безотказное функционирование вычислительных средств. Многие корпоративные компьютерные системы должны работать постоянно. Так, для служб экстренной помощи потеря времени зачастую означает потерю человеческих жизней. В мире бизнеса упущенные секунды становятся причиной упущенной прибыли. Тем, кто должен постоянно поддерживать работоспособность компьютера в подобных средах, необходимы соответствующие аппаратные и программные инструменты, особенно если они имеют дело с приложениями на базе Windows.
Все чаще технологии Microsoft выбирают как платформу для работы современных ответственных приложений. Сегодня ОС Windows рассматривается в качестве рентабельной, гибкой и легко управляемой альтернативы UNIX или иным сходным технологиям (рис. 1). Операционной системе Windows доверяют выполнение основных корпоративных приложений, включая электронную почту и управление производственными процессами, работой центра обработки заказов, электронной коммерцией и онлайновой торговлей.
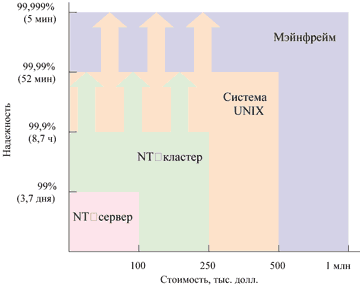 |
Рис. 1. Уровни надежности различных систем.
|
Однако без надежных решений высокой готовности компании рискуют столкнуться с дорогостоящими простоями. Непроизводительные потери времени и иные виды отказов могут привести к потерям в торговле, плохому обслуживанию заказчиков, снижению лояльности потребителей, уменьшению производительности, нарушению оговоренных сроков при реализации проектов. Эти потери могут к тому же осложняться утратой данных во время отказов.
Издержки от простоев
|
По данным Gartner Group, простой длительностью более часа в таких областях
бизнеса, как брокерские сделки, авторизация кредитных карт, бронирование и продажа
билетов, доставка посылок, работа ATM, может привести к потерям от сотен тысяч
до миллионов долларов.
Чтобы реализовать все преимущества на ОС Windows, ИТ-профессионалам требуется четкий план действий по устранению издержек от простоев. В настоящее время имеется несколько технологий предотвращения простоев и защиты данных в случае отказа.
Как избежать простоев и защитить данные
Причины вынужденного бездействия разнообразны, и нет универсального "лекарства" от таких проблем. Как известно, простой может быть вызван самыми разными факторами, включая перебои в подаче электропитания, природные катастрофы и выход из строя компьютерных компонентов. Единственный способ защитить данные от различных по природе отказов — инвестировать средства в систему, являющуюся полностью избыточной. Избыточность — одна из основных характеристик и фундаментальное условие для системы, которая должна быть способна выполнять восстановление после сбоя или же скрывать результаты отказа. Система с избыточностью обеспечивает мгновенное резервирование в случае отказа любого компонента основной системы.
Важнейший аргумент при выборе системы высокой готовности — ее способность защитить данные в случае отказа. Известно, что серьезные последствия для ответственных деловых приложений могут оказаться результатом утраты одной-единственной транзакции. Вот несколько примеров: производящая компания, теряющая тысячи долларов из-за неудачи в выполнении группового процесса; нарушение работы центра обработки экстренных вызовов, связанных с угрозой жизни, из-за оставшихся без ответа звонков.
Существует два наиболее общих подхода к обеспечению высокой готовности: это пассивные избыточные системы (кластеры) и активные избыточные системы (отказоустойчивые системы). В каждом из этих подходов используется избыточность, однако эта избыточность достигается различными путями. Важнейшее отличие между этими системами состоит в том, что пассивные избыточные системы способны восстанавливаться после сбоя, а активные системы вообще не теряют своей работоспособности.
Чтобы сделать осознанный выбор технологии обеспечения высокой готовности, необходимо понимать, как эти системы работают, в чем их преимущества и недостатки.
Пассивные избыточные системы
В таких решениях до момента возникновения сбоя приложения выполняются в единственной системе. После возникновения неисправности оператор или вторая система обнаруживают ее, и начинается процесс восстановления. При этом задействуется система резервного копирования, и выполнение задачи переносится с первичной на дублирующую систему. Кроме применения кластеров, из важных черт системы можно отметить автоматическое резервирование, т. е. периодическое копирование избранных файлов на другую систему, которая может быть перезагружена в случае отказа первой. Кроме того, могут использоваться резервные серверы, которые обеспечивают копирование файлов с одной системы на другую, а также слежение за приложениями и пользователями.
В простейшей системе оператор физически перемещает диски из сбойной системы в резервную. В более сложных системах резервная система "информирована" о пользователях и приложениях, выполняющихся в основной системе. На ней также расположена копия данных пользователя или организован доступ к ним. Резервная система автоматически перезагружает приложения и выполняет автоматическую регистрацию пользователей. Этот процесс называется failover — восстановление работоспособности после сбоя.
После этого можно проводить ремонт отказавшей системы. Для ввода исправленной системы в работу обе системы должны быть отключены и перезагружены, чтобы обеспечить перераспределение дисков на шине SCSI и переназначение пользователей на два процессора.
Известно, что в архитектуре Microsoft Windows Server Cluster первичная система выполняет всю обработку, в то время как страховочная система находится в резерве (в кластерной архитектуре "активный-активный" резервный сервер может использоваться для другой работы, пока в нем не возникнет необходимость). Программное обеспечение кластеризации использует выделенное горячее соединение между машинами для мониторинга операций и инициирования процедуры восстановления. Устройства могут совместно использовать общую шину SCSI для доступа к избыточным массивам памяти. При возникновении сбоя обработка приостанавливается до тех пор, пока система восстановления после сбоя не загрузит приложения и не произойдет возврат в работоспособное состояние. В типичных случаях на восстановление уходит две минуты и более.
Как показано на рис. 2, на сервере A кластерной конфигурации выполняется приложение пользователя и проводится мониторинг работы сервера. Если система мониторинга обнаруживает отказ на сервере A, то инициируется сервер B и все операции перемещаются на него. Серверы A и B совместно используют диск с важнейшими инструкциями по восстановлению после сбоя и пользовательской информацией. Этот диск представляет собой уязвимое место системы, единичную точку возможного отказа.
 |
Рис. 2. Простой двухузловой кластер.
|
Таким образом, простая кластерная архитектура обеспечивает механизм восстановления, благодаря которому один процессор может подхватить работу другого в случае отказа. Специальные приложения, "знающие" о существовании кластера, позволяют после процесса восстановления поддерживать работу приложения на сервере B. К сожалению, кластерные системы не обеспечивают безотказной работы, при которой циклы восстановления прозрачны для пользователя. Эти системы не обеспечивают ни непрерывности обработки, ни защиты данных. Приложения и данные не защищены от физической угрозы или катастрофы.
Специалисты IDC полагают, что в ряде случаев кластер и ПО высокой готовности
сложны в установке, конфигурировании и каждодневном использовании, а также что
квалифицированный персонал, способный обеспечивать управление кластером, найти
нелегко и обходится он недешево. Таким образом, кластеры и другие пассивные
избыточные системы имеют следующие недостатки.
- Эти системы сложны в установке и конфигурировании.
- Восстановление после сбоя проблематично. Многие приложения и даже некоторые
компоненты так называемых адаптированных для кластеров приложений не будут
работать после восстановления. Даже для кластерных приложений Windows 2000
этот процесс может занимать несколько минут. - Пользователи теряют данные, падает производительность их работы, возникают
паузы на время отработки неисправности, процесса восстановления и повторного
запуска процессов. Несохраненные данные утрачиваются, а выполнявшиеся транзакции
остаются незавершенными. После сбоя также могут ухудшаться характеристики
системы. - Создание специализированных сценариев восстановления после сбоя обходится
очень дорого, требует много времени на управление и ограничивает возможности
разработки приложений. - Регулярные профилактические мероприятия и резервное копирование, необходимые
для поддержания работоспособности кластера, сложно реализовать для приложений
круглосуточной работы. - Информационные системы уязвимы для ошибок операционной системы.
- Система обеспечивает восстановление после сбоя, но не предотвращает сбои.
Активные избыточные системы
Другая категория решений для Microsoft Windows использует технологии активной избыточности для поддержания готовности и защиты данных. В таких системах используются две составляющие, каждая из которых способна самостоятельно выполнять работу в полном объеме; таким образом, обе системы исполняют одни и те же инструкции параллельно. В случае отказа одной из систем другая продолжает работу, улучшая тем самым общую надежность системы. В наиболее надежных системах реплицируются все элементы, что делает их прозрачными для любого отдельного отказа.
Эти по-настоящему устойчивые к отказам системы гарантированной надежности позволяют обнаруживать большинство отказов и исключать неисправные компоненты менее чем за секунду, обеспечивая круглосуточную работу, с возможностью замены неисправных компонентов и модернизации оборудования в онлайновом режиме. Поскольку имеется как минимум два процессора, одновременно манипулирующих одинаковыми данными, отказ любого компонента остается невидимым как для приложения, так и для пользователя.
Существует два типа активных избыточных систем: один — со специализированным аппаратным обеспечением сервера, операционной системой и прикладным ПО со специальными модификациями, и другой — открытые системы.
Закрытые системы
Специализированные отказоустойчивые решения, которые значительно повышают надежность вычислительных средств и сокращают время их непроизводительных простоев, применяются тогда, когда стоимость этих простоев слишком велика, а нарушение работоспособности компьютеров может привести к катастрофическим последствиям, таким, как прекращение важнейших бизнес-процессов. Серьезную угрозу представляют, например, любые сбои при обработке в режиме реального времени транзакций по кредитным картам. В подобных ситуациях компании, не считаясь с затратами, стремятся обеспечить безотказную работу вычислительных комплексов.
Закрытые системы требуют множества специальных модификаций кода, которые могут быть довольно дорогостоящими. ПО и драйверы таких систем должны быть приспособлены к этим системам. Программное обеспечение (как ОС, так и приложения), а также дисковые системы должны соответствовать требованиям специфического интерфейса прикладного программирования (API), определяемого системной архитектурой. В результате стандартному ПО и драйверам, написанным для автономных систем, оказывается непросто воспользоваться преимуществами дополнительной надежности, когда ПО загружается в одну из этих избыточных конфигураций.
Хотя эти системы по-настоящему отказоустойчивы, они привязывают пользователей к закрытому ПО и технологиям поставщика. При этом пользователи оказываются зависимы от способности продавца регулярно обновлять свои продукты для поддержания систем на уровне требований современных технологий, они вынуждены приобретать все комплектующие (накопители, устройства ввода-вывода и т. п.) именно у этого поставщика. Данное обстоятельство ограничивает пользователей в выборе ПО и драйверов, которые они могут использовать.
Таким образом, отказоустойчивые системы характеризуются относительно высокой стоимостью, зато обеспечивают гарантированную надежность, что необходимо для приложений, выполняющих большой объем транзакций и/или не терпящих даже кратковременного прерывания вычислений. Системы высокой надежности стоят меньше и используются там, где задержка вычислений на период до нескольких минут не столь критична. Примерами приложений, требующих отказоустойчивости, можно считать банковские, биржевые программы, системы обслуживания пластиковых карточек и т. д. Интернет- и интранет-серверы, системы поддержки принятия решений, бухгалтерия — стандартные области применения систем высокой надежности. Кстати, банки входят в число основных потребителей отказоустойчивой техники. Причем если для банковской системы наиболее существенна гарантия сохранности информации, то для подсистемы, отвечающей за процессинг, важна полная отказоустойчивость.
Открытая архитектура
Решение корпорации Marathon Technologies (http://www.marathontechnologies.com)
— Marathon Assured Availability представляет собой альтернативу закрытым системам.
Немаловажно, что по стоимости оно сравнимо с кластером. Данное решение объединяет
стандартные Intel-серверы, стандартную ОС Windows и готовые приложения с поставляемыми
Marathon Technologies межсоединениями и ПО. В результате обеспечиваются низкая
закупочная стоимость, гарантированная готовность и устойчивость к катастрофическим
отказам при очень низкой совокупной стоимости владения.
Как работает решение Marathon
Для решения проблем отказоустойчивости Marathon Technologies использует специальную конфигурацию, которая позволяет сравнивать результаты вычислений с нормальным выполнением. Этот процесс прозрачен как для операционной системы, так и для приложения. Система работает, выполняя одно и то же приложение и транзакции на двух идентичных синхронно работающих серверах одновременно. Если один из серверов остановится из-за неисправности или физической угрозы, другой будет продолжать работать без простоев, не теряя времени на восстановление, и без пропусков транзакций.
Кроме того, каждый из двух серверов физически и логически разделяется на два, выполняющих два основных типа операций — это манипулирование данными с их преобразованием (обработка данных) и перемещение данных на системы хранения и обратно по сетям и через иные устройства ввода-вывода.
Как показано на рис. 3, функция обработки данных выполняется на вычислительных элементах (Compute Element) CE1 и CE2, а функция ввода-вывода — на элементах процессоров ввода-вывода (I/O Processor) IOP1 и IOP2. Два сервера соединены при помощи высокоскоростных интерфейсных плат PCI, называемых Marathon Interface Cards (MIC), и волоконно-оптического кабеля. Элементы MIC пересылают данные и получают их от двух систем одновременно. MIC также обеспечивает логику сравнения и тестирования, которая следит за идентичностью результатов от двух систем.
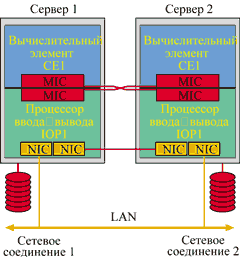 |
Рис. 3. Архитектура Marathon Assured Availability.
|
Каждый сервер представляет собой законченное устройство, с серверной версией ОС Windows, выполняющейся как на CE, так и на IOP. Все запросы на операции ввода-вывода от CE перенаправляются для обработки на IOP. На IOP выполняется ПО Marathon в виде приложения, контролирующего процесс управления всеми неисправностями, зеркалированием дисков, системным управлением и задачами ресинхронизации.
Соединив два идентичных сервера, как показано на рис. 3, легко получить конфигурацию системы Marathon Assured Availability. На двух CE-элементах этой конфигурации работает патентованная технология синхронизации компании Marathon, а также операционная система и приложения.
Система обеспечивает функциональность RAID-массива уровня 1 без специального контроллера RAID путем репликации операций записи на диски на каждом элементе IOP (зеркалирование дисков). В случае отказа одного из CE другой сервер продолжает работать, причем пауза будет невоспринимаемой и составит всего несколько миллисекунд (они требуются системе для удаления неисправного сервера из конфигурации).
Затем неисправный CE можно физически удалить, отремонтировать и вновь включить в систему. Далее через высокоскоростное соединение CE автоматически возвращается в конфигурацию путем переноса данных и ресинхронизации статуса работающего CE и восстановленного сервера. Статус операционной системы и приложений устанавливается в течение нескольких секунд, требуемых на ресинхронизацию двух CE, не оказывая воздействия на работу пользователей.
Этот подход в корне отличается от ресинхронизации кластера. То же относится и к IOP — при отказе одного из них другой продолжает обслуживать систему. Неисправный процессор IOP физически удаляется из системы, ремонтируется и возвращается в систему. После начала работы ПО Marathon восстановленный процессор IOP автоматически включается в конфигурацию. Повторное зеркалирование дисков выполняется в фоновом режиме через частную сеть Ethernet, соединяющую два процессора IOP. Отказ одного из зеркалированных дисков обрабатывается при помощи того же процесса.
Сетевые соединения системы также полностью избыточны. Сетевые соединения от каждого процессора IOP реагируют на тот же самый MAC-адрес, при этом только одному процессору разрешается передавать сообщения, но принимают их оба. Таким образом, одно сетевое соединение осуществляет мониторинг другого по частной сети Ethernet.
Если какое-либо сетевое соединение перестает работать, это обнаруживается процессором IOP, и оставшееся соединение будет обрабатывать рабочую нагрузку. Чтобы инициировать ремонт, система отправляет уведомление администратору.
На рис. 3 оба соединения принадлежат единому сетевому сегменту, но это необязательно. Сетевое соединение каждого процессора IOP может принадлежать разным сегментам одной сети. Система также способна работать с несколькими сетями, каждая со своими собственными избыточными соединениями. Чтобы система Marathon удовлетворяла дополнительным требованиям устойчивости к катастрофам, необходимо лишь оптоволоконное соединение. Поскольку CE остаются синхронизированными даже на таком расстоянии, отказ компонента или всего локального комплекса проходит незамеченным пользователями.
Уровни готовности
Архитектура Marathon Assured Availability обеспечивает не только аппаратную отказоустойчивость, но и имеет патентованную защиту от временных ошибок ОС, обладая способностью обнаруживать сбой ОС с последующим автоматическим перезапуском.
Поскольку на процессорах IOP работает ПО управления вводом-выводом и обработки ошибок, они изолированы от нагрузок процессоров CE, связанных с приложениями пользователей и операционной системой. Процессоры IOP работают параллельно, но не синхронно. Поскольку процессоры IOP обрабатывают все прерывания, процессоры CE освобождены для выполнения ОС и пользовательских приложений. Прерывания управляются через структурированный процесс, который устраняет основной источник отказов ПО, вызванный асинхронностью. Процессоры IOP подвержены этим асинхронностям, но поскольку два автономных IOP организованы в виде отказоустойчивой системы, асинхронность ПО, вызванная прерываниями, окажет воздействие только на один процессор IOP. Если IOP выйдет из строя, второй, работоспособный процессор IOP продолжает выполнять работу до завершения автоматической перезагрузки отказавшего IOP.
Программная устойчивость к внешним воздействиям
Эта изоляция и структурированная обработка программной среды системы ввода-вывода как в CE, так и в IOP, обеспечивают уровень отказоустойчивости ОС, недоступный в любой иной системе. Данная особенность системы является предметом патента, выданного компании Marathon.
По выбору пользователя ПО Marathon может быть сконфигурировано на автоматическую перезагрузку ОС и обеспечение доступности системы для пользователей до тех пор, пока та же программная ошибка не обнаружит себя вновь. Следует отметить, что разработанная архитектура также предлагает процессорам IOP возможность следить за работой приложений, выполняющихся на процессорах CE, и перезапускать "зависшее" приложение.
Устойчивость к катастрофам
Вообще говоря, катастрофоустойчивой называется система, способная обеспечивать высокую готовность приложений и доступа к данным в экстремальных условиях, например, во время стихийных бедствий или теракта. Обычно полагают, что существует два вида катастрофоустойчивости, которые необходимо учитывать при разработке подобных систем: локальный и дистанционный. В первом случае речь идет о локализованном чрезвычайном происшествии, таком, как пожар или непреднамеренное активирование системы пожаротушения. Во втором — о более масштабных бедствиях и происшествиях, таких, как землетрясения и террористические акты. Разнесенные модули катастрофоустойчивых систем размещаются отдельно друг от друга на расстоянии одного или нескольких километров, обеспечивая работоспособность системы в случае бедствия или чрезвычайного происшествия, благодаря тому, что самостоятельно работающие элементы находятся на расстоянии, обеспечивающем безопасность всей системы.
Marathon Assured Availability считается отказо- и катастрофоустойчивым решением (активным или пассивным), которое обеспечивает защиту от отказов и физических разрушений, как локальных, так и удаленных. Два сервера, составляющих каждую систему гарантированной готовности Marathon Assured Availability, благодаря функции SplitSite могут располагаться на расстоянии до 55 км, обеспечивая оптимальную защиту от катастроф. Каждая из систем может быть размещена в различных физических средах и укомплектована резервными блоками питания и системами безопасности таким образом, что если одна из систем будет уничтожена, другая продолжит бесперебойную работу.
Управление системой
В отличие от иных систем, Marathon Assured Availability имеет три состояния: рабочее, уязвимое и неисправное. В уязвимом состоянии система невидимо для пользователей уведомляет администратора о возможности начала цикла ремонта (ресинхронизации). Есть два метода уведомления об уязвимом состоянии: через системную консоль и через журнал событий.
Системная консоль обеспечивает графическую модель, информация о которой отображается на системном мониторе, на удаленных системах (по сети или по последовательной линии). Компоненты имеют цветовую кодировку состояния, а для проверки и управления системой используется простой интерфейс.
Второй метод использует журнал событий Windows-сервера для регистрации всех событий, включая события системы Marathon. Имеется несколько программных средств сторонних разработчиков, которые пользователи используют для передачи информации о событиях системному администратору через устройства звуковой сигнализации, по факсу, электронной почте и т. п.
На базе рассмотренной архитектуры корпорация Marathon Technologies предлагает
решение Endurance 6200.
"Три за три"Одна из характеристик архитектуры Marathon Assured Availability — способность
Вообще говоря, существует множество интересных способов применения этой Таким образом, кластерная система высокой надежности использует пассивную |

Заключение
В компьютерной отрасли существуют противоречивые мнения по поводу концепции высокой готовности, отказоустойчивости и устойчивости к воздействию катастроф. Чтобы выбрать оптимальное для конкретного случая решение, важно уяснить себе, как работают системы с активной и пассивной избыточностью, а также учесть все возможные проблемы и решить, какую величину времени простоя можно допустить.
Представители Marathon Technologies утверждают, что общая стоимость владения их компьютерными системами меньше, чем кластерными, но некоторые аналитики полагают, что ИТ-менеджерам следует самостоятельно просчитать эти расходы. Не следует также забывать о масштабируемости. Технология Marathon Assured Availability не поддерживает SMP-архитектуры. Фирма-производитель указывает на затраты на ПО кластеризации, тестирование отказоустойчивости, обучение персонала и обслуживания как на аргументы в пользу приобретения их решений, а не кластерных систем. В компании также подчеркивают, что подписанное соглашение с Microsoft предусматривает приобретение только одной лицензии на Windows или Exchange Server на систему.
Стоит еще раз подчеркнуть, что системы гарантированной готовности Marathon Assured Availability обеспечивают готовность 99,999%. В отличие от закрытых систем других поставщиков решения Marathon строятся на стандартных Intel-серверах, использующих ПО Microsoft Windows без ухудшения готовности. Соединение стандартного аппаратного обеспечения и готового ПО создает рентабельное, простое в управлении решение с низкой совокупной стоимостью владения.
Сразу после появления технологии Marathon Assured Availability ею заинтересовались и гранды компьютерной индустрии. Так, корпорация Hewlett-Packard дополнила существующие кластерные решения для платформы Intel совместной с Marathon Technologies разработкой NetServer Assured Availability Solution с использованием двух симметричных пар серверов.
Большой интерес к данной технологии проявили и фирмы, производящие модульные (blade) серверы. Так, в прошлом году было подписано соответствующее соглашение между Marathon Technologies и Nexcom International.