Архитектура высоко-производительных вычислений: процессор Alpha EV7
Сергей Петраков
Первоначальный план развития архитектуры Alpha, разработанный корпорацией DEC в 1988 г., был рассчитан не менее чем на 25 лет. Разработчики полагают, что сейчас, по прошествии 15 лет, технология Alpha, унаследованная сперва компанией Compaq, а затем от нее — Hewlett-Packard, уже достигла совершенства.
Напомним, что версия архитектуры Alpha, обозначаемая как EV6, впервые была опубликована на Микропроцессорном форуме в 1996 г. Процессор EV6, известный также под кодом 21264, был построен на четырехканальном суперскалярном ядре, поддерживал выполнение до 80 команд за такт и режим внеочередного исполнения. В EV6 было предусмотрено 80 целочисленных регистров и 72 регистра для операций с плавающей точкой. Файл целочисленных регистров дублировался для ускорения доступа, и каждое целочисленное АЛУ получало свой регистровый файл, к которому оно может быстро обращаться. Передача и совместное использование данных занимали один такт.
Кэш-память первого уровня L1 имела объем 64 Кбайт и обеспечивала доступ с задержкой в два такта. Предполагалось, что такой размер кэш-памяти обеспечивает оптимальный баланс времени доступа и процента попаданий. При меньшем размере кэш-памяти L1 время доступа сократилось бы до одного такта, но снизился бы процент попаданий.
Процессор Alpha 21264 имеет достаточно длинный конвейер из семи ступеней. Как известно, для защиты от нарушения работы конвейера из-за прерывания команд в высокопроизводительных процессорах используется предсказание ветвлений. При неправильном предсказании задержка для кристалла 21264 составляет не менее 11 тактов. Это время уходит на повторное заполнение буфера и ожидание в очереди запросов команд на выполнение. Метод предсказания в кристалле 21264, использующий таблицу историй ветвлений, сочетает локальное и глобальное предсказание. Для ускорения выборки предсказанной команды в кэш-памяти 21264 предусмотрена строка для хранения предсказанных команд.
Процессор следующего, четвертого поколения — Alpha 21364 с кодовым названием EV7 был представлен на Микропроцессорном форуме в 1998 г. Идеи, приведшие к его созданию, были впервые обнародованы в 1996 г. в статье разработчика идеологии Alpha Дика Сайтса It's the Memory Stupid ("Когда подводит память"). Сайтс выявил фундаментальную проблему, встающую при создании новых серверных процессоров. Оказалось, что для повышения производительности системы надо не только увеличивать тактовую частоту ядра процессора, но улучшить такие показатели, как пропускная способность и задержка при обращении к памяти. Как писал Сайтс, при анализе работы ядра кристалла 21164, работающего с тактовой частотой 400 МГц, оказалось, что в среднем каждые три такта из четырех тратились на ожидание данных из основной памяти. Для повышения скорости вычислений следовало не повышать производительность ядра, а обеспечивать более быстрое получение им данных и команд.
Хотя в системе EV7 используется ядро от 21264, к нему добавлены совершенно новые межпроцессорные линки, встроенный контроллер памяти и кэш-память второго уровня L2 большого объема.
Первоначально кристалл 21364 (EV7) имел тактовую частоту 1,2 ГГц и выпускался
с соблюдением проектных норм 0,18 мкм. В дальнейшем планируется переход на более
жесткие нормы 0,13 мкм при использовании технологического процесса "кремний
на изоляторе" (SOI). Соответствующий продукт с кодовым названием EV79 будет
работать с более высокой тактовой частотой и потреблять меньше энергии. Микросхема
EV7 имеет большой, но тем не менее соответствующий современным нормам размер
кристалла — 400 мм2. Новые технологии изготовления позволят уменьшить размер
кристалла на 33%, а использование в процессоре каналов памяти Rambus и каналов
для межпроцессорных соединений обеспечивает масштабируемость по частоте и пропускной
способности.
Эволюция AlphaВ феврале 1992 г. Digital Equipment Corporation (DEC) представила 64-разрядную Первой в семействе микропроцессоров Alpha появилась модель 21064 (кодовое Буквы EV в обозначениях моделей кристаллов означают Extended VAX, так В 1994 г. корпорация DEC представила новый микропроцессор семейства Alpha В декабре 1998 г. был объявлен новый микропроцессор Alpha — 21264 (EV6). Первоначально кристаллы 21264 (EV6) создавались с соблюдением проектных |
С чего начинаются серверы
Итак, процессоры EV7 (кодовое название Marvel, рис. 1) построены на ядре 21264 (EV6), которое со времени его появления мало изменилось. Для усовершенствования обработки команд (которые стали более многочисленными) число заполняемых блоков кэш-памяти увеличено с 8 до 16. В EV7 используется иерархическая организация памяти. При отсутствии нужных данных в кэш-памяти первого уровня L1, имеющей объем 64 Кбайт, происходит обращение к кэш-памяти второго уровня L2 (1,5 Мбайт). Если данные находятся там, они передаются по 128-разрядной шине. Ссылки на данные, которые отсутствуют в кэш-памяти L2, обращаются к локальной памяти. Обращение по адресу вне локальной памяти передается по сети к памяти другого процессора в системе.
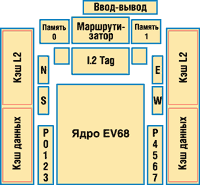 |
Рис. 1. Схема кристалла EV7.
|
Ядро 21264 имеет 8-входовой буфер, который сейчас используется как для кэш-памяти L1, так и для L2. В новом кристалле EV7 размер этого буфера увеличен до шестнадцати 64-разрядных блоков в L1 и L2. Новый буфер используется для хранения результатов успешных попаданий, оставляя кэш-память L2 для локальной памяти или сети. Благодаря такой буферизации строки быстрее записываются в кэш-память, освобождая доступ для процессорного ядра. Большой объем буферов необходим для поддержки увеличенного числа процессоров и межпроцессорных соединений.
Процессорное ядро EV6 включает конвейер из семи ступеней с доступом к кэш-памяти L1 за два такта. За каждый такт из двухканальной, частично ассоциативной кэш-памяти (I-кэш) емкостью 64 Кбайт извлекаются четыре команды. Они направляются к целочисленным устройствам или устройствам с плавающей точкой. Целочисленные команды проходят стадию декодирования, в которой могут быть задействованы 32 виртуальных и 80 физических регистров, и помещаются в очередь на выполнение.
На каждом такте очередь целочисленных команд выдает до четырех команд (первой — самую старую), извлекаются пустые ячейки (для устранения "дыр" от ранее выданных команд) и принимаются новые команды от декодировщика. Для более быстрой передачи регистров четыре целочисленных блока совместно используют две независимые копии файла регистров.
Двухканальная частично ассоциативная кэш-память данных (D-кэш) имеет емкость 64 Кбайт. Ссылки, которые определяют данные в кэш-памяти первого уровня, объединяются в блоке запроса для обращения к кэш-памяти второго уровня L2. Модифицированные данные вытесняются при заполнении и записываются в 16-входовом буфере.
Процессор EV7 включает частично ассоциативную шестиканальную кэш-память второго уровня L2 емкостью 1,5 Мбайт. Одним из результатов повторного использования архитектуры ядра EV6 стала задержка на 12 тактов между загрузкой и использованием — она устанавливается управляющими элементами ядра. Преимущество такой достаточно продолжительной задержки — значительное сокращение энергопотребления массива L2. Кэш-память L2 может читать или записывать 16 байт за цикл с частотой 1 ГГц, что позволяет получить скорость чтения и записи на уровне 16 Гбайт/с. Массив L2 использует механизм ECC с исправлением одиночных ошибок и обнаружением двойных.
Почему RDRAM
Один из факторов, снижающих пропускную способность вычислительной системы, — это "фронтальная" шина (front-side bus) процессора, работающая в несколько раз медленнее самого процессора. До недавнего времени эта шина оказывалась узким местом, поскольку ее всегда задействовали при обращениях к памяти, операциях ввода-вывода и поиска в кэш-памяти. Для доступа к основной памяти требовалось маршрутизировать запросы через другой кристалл, работающий на скорости шины динамической памяти DRAM. Разработчики микропроцессоров пытались максимально приблизить запросы на память к ядру процессора. Большинство высокопроизводительных процессоров сейчас оборудованы встроенной кэш-памятью L2 — современные серверные процессоры имеют объем вторичной кэш-памяти 1 Мбайт и выше. В кристалле EV7 ее размер составляет 1,5 Мбайт, что обеспечивает баланс между размером кэш-памяти и размером кристалла.
Микросхема EV7 содержит два интегрированных контроллера памяти Direct Rambus (RDRAM). Архитектура Direct Rambus обеспечивает высокую пропускную способность и низкие задержки при обращении. Кроме того, в ней используется передача пакетов, что оптимально для сетей межпроцессорных соединений. Задержка между сигналами на контактах при попадании на страницу памяти для RDRAM составляет 30 нс, а задержка при обращении — 75 нс.
Сейчас выбор памяти RDRAM может показаться спорным, но в 1998 г. она считалась будущим стандартом высокопроизводительной памяти. С технической точки зрения RDRAM обеспечивала более высокую пропускную способность на контакт, чем любая другая современная стандартная память. По выделенной пропускной способности памяти EV7 превосходит все серверные процессоры — благодаря наличию в нем встроенного двойного контроллера памяти RDRAM. Контроллеры поддерживают до 2048 одновременно открытых страниц. Каждый из них поддерживает четыре 18-разрядных канала RDRAM, в результате каждый процессор получает более 12 Гбайт/с физической пропускной способности. Пятый канал предназначен для реализации RAID для памяти, обеспечивающей максимальную защиту от ошибок. Вообще говоря, этот пятый канал RDRAM предназначен для конфигурации памяти типа RAID и защищает от отказа в любом другом канале. Если ECC обнаружит многобитовую ошибку, происходит повторное обращение к данным с отключенным одним каналом. Каналы отключаются по очереди до тех пор, пока не будет получен правильный пакет ECC.
Как и кэш-память L2, оперативная память использует механизм ECC с исправлением одиночных ошибок и обнаружением двойных. Данные из оперативной памяти передаются пакетами, включающими 9-разрядный код ECC. Ошибки можно корректировать "на лету" без внесения дополнительной задержки или снижения пропускной способности.
Если требуется обеспечить дополнительную защиту от ошибок в памяти (а вероятность ошибок возрастает по мере приближения объемов оперативной памяти к терабайтному рубежу), конфигурация RAID дает более высокую надежность, позволяя сохранить работоспособность машины даже в случае отказа целого модуля RIMM. Обнаружение ошибки вызывает небольшое запаздывание, после чего кристалл возобновляет работу с прежней пропускной способностью и задержкой, одновременно исправляя ошибку. Как уже отмечалось, для конфигурации RAID нужен дополнительный канал RDRAM, соединенный с другими четырьмя каналами по схеме поразрядного "исключающего ИЛИ", которая обеспечивает необходимую информацию для восстановления в случае отказа одного из основных каналов.
Протокол обеспечения когерентности кэш-памяти на основе каталога — составная часть контроллера памяти. Каждая запись в каталоге связана с одним 64-разрядным блоком в кэш-памяти. Запись в каталоге сообщает пользователю о состоянии блока данных, которое может принимать одно из трех значений. Данные считаются локальными (local), если они находятся в оперативной памяти или кэш-памяти локального процессора. Данные могут совместно использоваться (shared), при этом несколько процессоров могут хранить их неизмененную копию в своей кэш-памяти. При небольшом числе совмещений в каталоге можно записать идентификационные номера процессоров, использующих данные. Однако при большом числе каталог переключается на векторное представление, при котором 20 разрядов обозначают область внутри машины. В 64-процессорной машине каждый бит будет представлять блок из четырех процессоров. Наконец, состояние exclusive означает, что процессор владеет эксклюзивной копией блока в кэш-памяти; в этом случае в каталог записывается адрес процессора, в кэш-памяти которого хранится блок.
Бит 36 физического адреса в EV7 определяет, будут ли последовательные адреса располагаться на одном процессоре или чередоваться между двумя. При линейном хранении задержка данных в месте, где они нужны пользователю (например, повторяющийся код), оказывается максимальной. При чередовании ссылки на данные, к которым обращаются несколько процессоров, распределяются между двумя процессорами. Это уменьшает вероятность того, что все нужные данные окажутся в памяти одного процессора и число обращений к нему резко возрастет.
Адресное пространство EV7 поддерживает до 128 узлов по 32 Гбайт памяти в каждом. Режим адресации должен устанавливаться при загрузке системы. В максимальной конфигурации система на базе 21364 может работать с памятью 4 Тбайт — этого более чем достаточно для большинства задач.
В протоколе когерентности кэш-памяти используются термины requester, home, shares и owner. Requester — это узел в сети, запрашивающий данные. Home — местонахождение каталога, представляющего данные, а также хранилища данных DRAM. Возможно, что имеется владелец (owner) блока — удаленный узел, содержащий в кэш-памяти эксклюзивную копию строки. Shares — удаленные узлы, которые могут содержать совместно используемую немодифицированную копию.
Сетевая масштабируемость и надежность
Кристалл EV7 построен в архитектуре ccNUMA (cache coherent, non-uniform memory architecture — архитектура разделяемой распределенной памяти с когерентной кэш-памятью). Средняя задержка при доступе к памяти здесь такая же, как у многих обычных серверных архитектур, но при этом обеспечивается гораздо большая масштабируемость. По максимально возможной длительности задержки EV7 мало отличается от стандартных процессоров и в данном отношении может рассматриваться как стандартная (не-NUMA) система. Но местные или ближние ссылки здесь работают значительно быстрее, чем в других архитектурах, и операционная система, поддерживающая NUMA, может воспользоваться преимуществами таких ссылок для повышения производительности сервера.
Уникальность 21364 связана с возможностями масштабирования. Память масштабируется по мере роста числа и скорости процессоров. Общая пропускная способность также масштабируется благодаря эффективным межпроцессорным соединениям (IP). Двухмерная топология межпроцессорных соединений позволяет построить сеточную структуру, обеспечивающую защиту от отказов и минимальное число переходов к самому дальнему процессору (рис. 2). Такая топология масштабируется до конфигурации из 128 процессоров, а более крупные конфигурации можно разбить на несколько мелких.
 |
Рис. 2. Конфигурация "плоский тор" с 16 процессорами.
|
EV7 легко масштабируется от 4 до 64 процессоров без использования специальных связующих компонентов. Протокол физических адресов поддерживает до 128 процессоров.
Каждый IP-канал способен передавать данные со скоростью 6,2 Гбайт/с, и общая пропускная способность на один процессор составляет 24,6 Гбайт/с. Каждый переход между соседними узлами в среднем занимает 18 нс. Поскольку в сети данные передаются пакетами с использованием схемы адаптивной маршрутизации, соблюдение порядка данных при доставке не гарантируется. Топология тора уменьшает максимально возможную задержку при передаче между узлами. Циклические маршруты могут привести к взаимной блокировке, и, чтобы решить эту проблему, для каждого маршрута создается виртуальный канал.
Протокол адаптивной маршрутизации позволяет сети обнаруживать и избегать возникновения "горячих точек". Алгоритм маршрутизации также предотвращает взаимную блокировку с помощью специального буфера, выделяемого каждому узлу. Чтобы не возникало взаимной блокировки, пакеты должны всегда направляться ближе к пункту назначения при каждом переходе к соседнему узлу.
Пакет также может оказаться в ситуации взаимной блокировки из-за соединения типа двухмерный квадрат. Для предотвращения взаимных блокировок в сети используется протокол, согласно которому пакеты перемещаются сначала только в одном направлении (восток — запад либо север — юг). Такая схема маршрутизации называется dimension-order (в порядке направлений). Например, маршрутизатор имеет четыре IP-соединения с соседними процессорами, которые условно обозначаются как восточное, западное, северное и южное (E, W, N и S). Маршрутизатор также соединяется с портом IO7 и локальными портами. Локальные порты — это порт Cbox локального процессора и два контроллера памяти Z0 и Z1 (рис. 3). Данные записываются во входную очередь. Одна из проблем сетей типа "очередь на входе" — трудность устранения задержек, накапливающихся на входе. EV7 оборудован двумя портами чтения для каждой очереди, поэтому можно считывать сразу два пакета из очереди и направлять их к любому возможному выходу. Все порты почти не отличаются друг от друга, за исключением порта ввода-вывода, у которого режим FIFO ("первым вошел, первым вышел") реализован аппаратно.
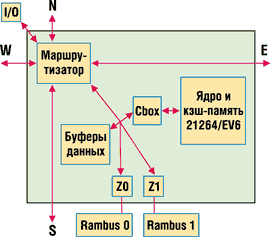 |
Рис. 3. Упрощенная схема межпроцессорных соединений.
|
Кристалл EV7 использует маршрутизацию на основе источника — выбираются биты
физического адреса, представляющие идентификатор и индекс процессора из таблицы
маршрутизации. Таблица маршрутизации включает координаты узла назначения (по
осям восток — запад и север — юг) и маршрут к нему. Когда пакет выдается в сеть,
он сначала направляется по направлению восток — запад в нужную сторону до тех
пор, пока координаты по этой оси не совпадут, а затем аналогично направляется
по оси север — юг; после совпадения обеих координат пакет извлекается из сети
в узле назначения. Начальные биты перехода используются для того, чтобы в сети
не образовались "дыры", и для восстановления после ошибки в сети. Например,
если пакет направлен на восток, но восточный линк по какой-то причине неисправен,
то начальный бит перехода перешлет пакет через северный порт, откуда его можно
будет отправить на восток. Такой механизм маршрутизации позволяет обходить неисправные
связи тороидальной топологической схемы.
Другая особенность сети — асинхронное взаимодействие процессоров, устраняющее необходимость в распределении высокочастотных точных часов по большой машине. Надежность улучшена за счет отказа от централизованной синхронизации, которая сама представляет собой единую точку отказа, т. е. компонент, отказ которого приводит к отказу всей системы. Подобно большинству процессоров, EV7 поддерживает высокие значения коэффициента "ядро — шина" для преобразования частоты процессора в частоту RDRAM или межпроцессорного соединения.
EV7 обеспечивает дополнительный порт ввода-вывода для каждого процессора, поэтому при добавлении в конфигурацию нового EV7 производительность ввода-вывода увеличивается. Пятый порт под названием IO7 обеспечивает обмен данными со скоростью 1,6 Гбайт/с со стандартными шинами PCI, PCI-X и AGP. Порт IO7 не отличается от процессорных портов, но предназначается для интерфейса со стандартными шинами, поэтому его тактовую частоту можно делить. Для поддержки PCI-X, AGP или некоторых других шин ввода-вывода в EV7 можно добавить микросхему ASIC. Пропускной способности порта IO7 достаточно для поддержки нескольких портов на одну ASIC ввода-вывода.
Заключение
По мнению многих экспертов, систему EV7 отличает великолепная масштабируемость, высокая скорость обмена данными с памятью и маленькая задержка доступа. Ядро процессора EV68 обеспечивает стабильную платформу для этой усовершенствованной архитектуры.
Хотя семейство Alpha близко к завершению своего жизненного цикла, данная технология оказала заметное влияние на индустрию. Многие конструкторы Alpha работают сегодня в Intel и Advanced Micro Devices, а такие концепции, предложенные инженерами Digital, как многопоточность, используются в последних версиях Pentium 4 и новейшей разработке AMD — процессоре Opteron.
Как уже отмечалось, примерно через год Hewlett-Packard собирается представить кристалл EV79, который будет выпускаться на усовершенствованных производственных линиях с соблюдением проектных норм 0,13 мкм с использованием технологии SOI, что приведет к дополнительному увеличению производительности. Новая микросхема EV7 сама по себе вряд ли привлечет огромное количество новых корпоративных клиентов, но ее выпуск важен для уже существующих пользователей процессоров Alpha, которым необходимо обновить свои системы. Дело в том, что компьютерные системы на этой платформе достаточно популярны сегодня в академических учреждениях и научно-исследовательских институтах. Они применяются для работы с приложениями, предъявляющими повышенные требования к вычислительным ресурсам. Так, национальная лаборатория в Лос-Аламосе использует Alpha-суперкомпьютер ASCI Q, рассчитанный на выполнение 30 трлн вычислений в секунду. С помощью этой гигантской системы с тысячами процессоров ученые имитируют ядерные взрывы.
Hewlett-Packard обещает обеспечить долгосрочную поддержку семейства AlphaServer.
Кроме того, маркетинговая программа HP Alpha RetainTrust предусматривает активную
поддержку заказчиков и их плавный переход на серверы, построенные на базе процессоров
Itanium.
Системы на базе EV7В начале 2003 г. Hewlett-Packard объявила о выходе нескольких новых моделей Основные характеристики серверов
На момент объявления модели число процессоров EV7 с тактовой частотой
Базовый блок новых серверов — это двухпроцессорный модуль, в который Последние версии Tru64 Unix V5.1B и TruCluster Server поставлялись заказчикам На момент выпуска серверы AlphaServer заняли первое место в отрасли по |

