Средства Data Mining в Microsoft SQL Server 2000
Антон Варфоломеев,
сертифицированный разработчик ПО (MCSD)
antonv@digdes.com
Термин Data Mining, переводимый обычно как извлечение данных, или интеллектуальный анализ, в последнее время встречается часто. Это связано в первую очередь с растущим интересом к данной теме со стороны предприятий малого и среднего бизнеса, а не только узкого круга специалистов, как это было несколько лет назад.
За время своей работы большинство предприятий успели накопить большие объемы данных и теперь стремятся извлечь из этих данных хранящиеся там “скрытые знания”. К числу таких знаний можно отнести ответы на вопросы, которые обычно задают менеджеры и аналитики: “Какие товары чаще всего продаются вместе?”, “Насколько вырастут продажи при снижении цены на n процентов?” и т. п. Ответы на эти вопросы и призваны дать приложения Data Mining.
Однако в реалиях российского рынка предприятие зачастую не имеет возможности приобрести отдельное приложение этого типа. Во-первых, цены на такие приложения “кусаются” — они могут доходить до нескольких тысяч долларов, в зависимости от класса приложения и его функциональных возможностей. Во-вторых, нужно также потратить средства на обучение персонала работе с новым инструментом. Все это в сочетании с естественным недоверием к новым разработкам отпугивает потенциальных клиентов Data Mining. Разумеется, многие предпочли бы использовать одно приложение, которое совмещало бы все функции, связанные с хранением, обработкой и добычей данных (зачем платить за три средства, когда можно использовать одно?). Что ж, выход есть. Таким универсальным средством является хорошо знакомый большинству предприятий пакет Microsoft SQL Server.
СУБД Microsoft SQL Server (а точнее, входящий в ее состав инструментарий Analysis Services) обзавелась собственными средствами добычи данных только в 2000 г., в рамках реализуемой корпорацией Microsoft стратегии BIA (Business Internet Analysis — аналитика электронной коммерции), цель которой — предоставление компаниям, занимающимся электронной коммерцией, возможности сбора и анализа данных о поведении клиентов интерактивных магазинов. Понятно, что столь узкая специализация резко ограничивает функциональность и области применения средств SQL Server как средства извлечения данных. Тем не менее, как мы убедимся позже, возможностей пакета вполне достаточно для рядового предприятия мелкого или среднего бизнеса. Но обо всем по порядку.
Из возможностей, предоставляемых SQL Server 2000, прежде всего перечислим следующие:
- построение и обработка моделей Data Mining;
- извлечение данных как из реляционных, так и из многомерных источников;
- два алгоритма добычи данных — Microsoft Decision Trees и Microsoft Clustering;
- расширения языка запросов к многомерным данным (MDX);
- работа с внешними приложениями через объектную модель DSO (Decision Support Objects).
Модели
Модели Data Mining — это основа извлечения данных в SQL Server 2000. По сути модель представляет собой совокупность метаданных, отражающих некоторые правила и закономерности в исходных данных. При этом структура модели определяет набор ключевых атрибутов анализа, тогда как ее содержание несет непосредственно статистическую информацию — здесь прослеживается сходство с идеологией обычных таблиц. Однако стоит иметь в виду, что на основе одного и того же набора исходных данных можно построить несколько различных моделей. В этом смысле построение правильной модели гарантирует нам получение именно тех “скрытых” данных, которые мы стремимся выявить. На рис. 1 показана структура модели, содержащая данные о покупателях магазина в разрезе приобретаемых ими товаров.
 |
| Рис. 1. Структура модели Data Mining.
|
Процесс построения модели реализован в Analysis Services в виде мастера, позволяющего шаг за шагом задать параметры модели и выполнить ее обработку, что, по мнению разработчиков, упрощает проведение анализа.
Выбор источника данных
Первый шаг в построении модели — выбор источника данных для анализа. Поддерживаются два типа источников данных: многомерные, используемые в рамках технологии OLAP (правда, пока в качестве OLAP-источника можно использовать только сам модуль Analysis Services), и более привычные — реляционные. Наличие первого варианта дает гораздо большую свободу выбора для анализа, ведь далеко не каждое предприятие имеет собственное многомерное хранилище данных.
После выбора источника можно приступать непосредственно к формированию структуры модели. Для этого нужно определить таблицу (или измерение, в случае многомерного источника), содержащую анализируемые данные, а также выбрать одно из полей таблицы (или показатель многомерного куба), которое будет находиться в фокусе исследования. Например, если вам нужно оценить риск кредита для определенных клиентов банка, то величину этого риска можно выбрать в качестве предмета исследования. Исходными данными для исследования в таком случае могут выступать данные о клиенте — возраст, годовой доход, наличие автомобиля, место жительства и т. п. Вообще говоря, выбор исходных данных и предмета анализа — процесс творческий, так что если не удалось получить требуемые оценки сразу, то попробуйте изменить структуру модели, введя в нее дополнительные атрибуты. Возможно, это позволит оценить ситуацию с другой точки зрения.
Выбор алгоритма анализа
Следующий важный шаг — выбор одного из двух алгоритмов анализа данных. Как уже говорилось выше, Analysis Services поддерживает два алгоритма — Microsoft Decision Trees и Microsoft Clustering. Поскольку области применения и результаты работы каждого из них могут сильно различаться, на этом шаге имеет смысл остановиться подробнее.
Алгоритм Microsoft Decision Trees основан на известном методе построения деревьев решений. В его рамках значение каждого из исследуемых атрибутов классифицируется на основе значений остальных атрибутов, с использованием правил вида “если — то”. Результат работы такого алгоритма — древовидная структура, каждый узел которой представляет собой некий вопрос. Чтобы решить, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня (наиболее близкий аналог такой структуры — дерево видов в биологии). Главное преимущество этого алгоритма — наглядность и простота использования. Однако область применения "древесного" метода ограничена в основном задачами классификации (такими, как приведенный выше пример с кредитными рисками).
Второй алгоритм, Microsoft Clustering, использует другой, не менее известный метод поиска логических закономерностей — метод “ближайшего соседа”. В процессе работы алгоритма исходные данные объединяются в группы (кластеры) на основе аналогичных или схожих значений атрибутов. Полученные наборы данных анализируются, что позволяет выявить скрытые закономерности или построить вероятностный прогноз. Данный алгоритм позволяет провести более глубокий анализ данных, чем дерево решений, но и он имеет свои ограничения. Его предпочтительно применять для наборов данных со схожими атрибутами, значения которых принадлежат определенному интервалу (например, возраст, годовой доход и т. п.). Однако в случае нетипичных, выпадающих из общего ряда значений атрибутов алгоритм может давать неверную оценку.
Выбор правильного алгоритма зависит от класса задачи, которую требуется решить, а также от состава исходных данных. Задачи классификации неоднородных данных лучше решать с помощью алгоритма деревьев решений, а задачи прогнозирования или выявления неявных закономерностей — с помощью метода кластеризации. Какой бы алгоритм вы ни выбрали, на этом построение модели окончено, и можно переходить к следующему процессу — тренировке модели.
Тренировка построенной модели — это не что иное, как процесс обработки исходных данных согласно выбранному алгоритму. Этот процесс может занять длительное время, особенно при больших объемах данных. После окончания тренировки исходные данные больше вам не понадобятся. В результате тренировки модель будет заполнена статистическими данными, которые могут быть представлены как в графическом, так и в цифровом виде.
Отображение результатов
Для отображения результатов анализа используются встроенные средства Analysis Services. При этом варианты отображения различны для каждого из алгоритмов. В качестве примера ниже приведены результаты работы алгоритма Microsoft Decision Trees.
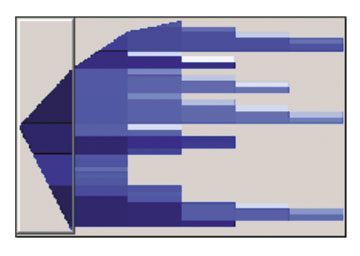 |
Рис. 2. Дерево решений.
|
Схема на рис. 2 показывает все ветви построенного дерева решений. Более темным цветом выделены ветви, соответствующие наибольшей вероятности (числу попаданий), а более светлым — наименьшей. В данном примере ветвей у дерева немного, однако в некоторых случаях их число может достигать нескольких сотен. Выделенная часть дерева отображается в режиме детального просмотра (рис. 3).
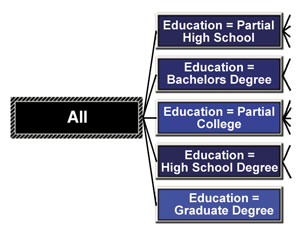 |
Рис. 3. Выбранная часть дерева решений.
|
Любую часть дерева решений можно выделить для детального просмотра, но при этом нельзя просматривать более двух уровней одновременно. На увеличенной части дерева можно видеть значения, присвоенные каждому из узлов в процессе работы алгоритма. Как и в режиме просмотра всего дерева целиком, цвет узла здесь сигнализирует о количестве попаданий исходных данных в эту ветвь. Выбор определенного узла дерева позволяет просмотреть статистическую информацию о данном узле в числовом виде. Эта информация включает в себя значение узла дерева, количество значений исходных данных, попавших в данную ветвь, и вероятность попадания (рис. 4).
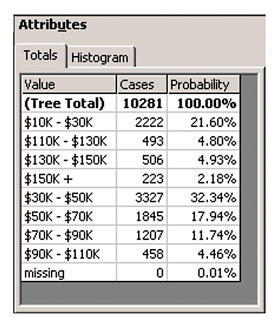 |
Рис. 4. Информация в числовой форме.
|
Итак, мы видим, что средства извлечения данных в SQL Server 2000 Analysis Services предоставляют достаточно богатый набор функциональных возможностей для аналитиков и менеджеров предприятий. К тому же данный инструментарий отличается простотой в использовании и невысокой ценой, и, думается, он сможет найти своих пользователей в среде российских компаний.